Word to Vector 後續討論
Efficient Estimation of Word Representations in Vector Space
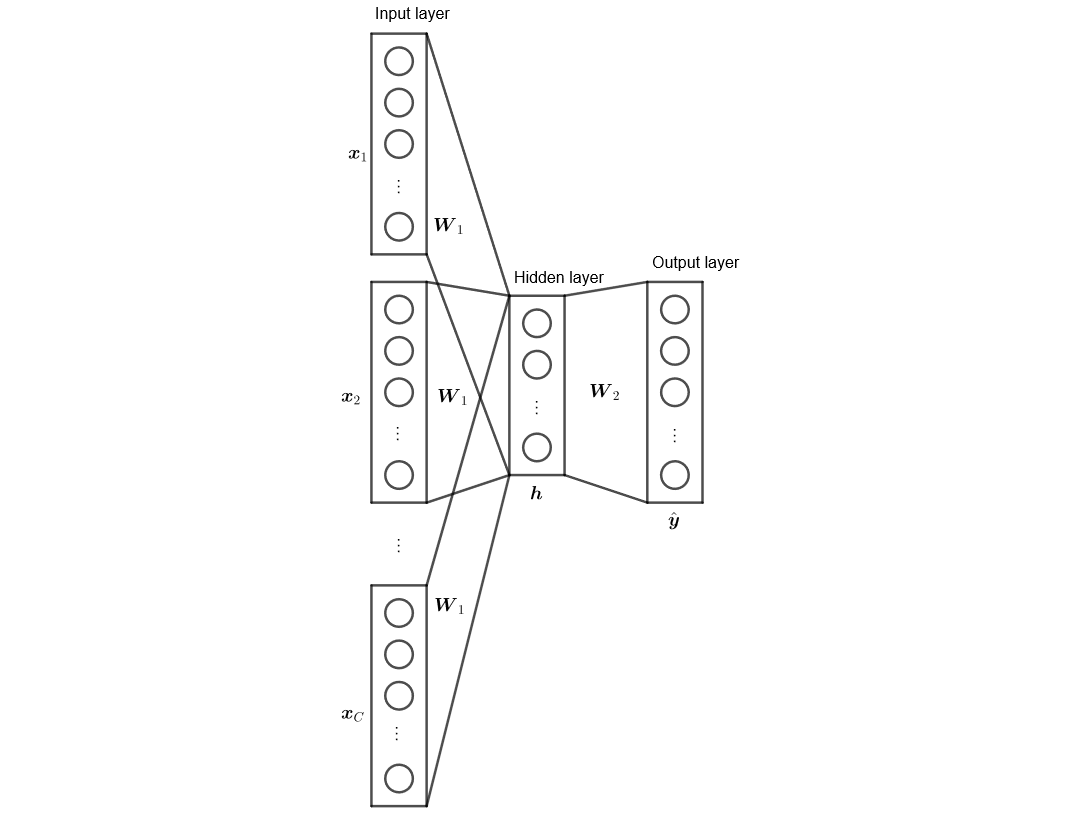
首先介紹由 2013 年由 Google 工程師開發的 CBOW 與 skip-gram 架構 [參考],與其發布版 Google's Word2Vec。
向量表示
當時常用方式是 N-gram,用機率模型計算詞序的出現機率,以此預測下一個單字,卻難以定義單字相似度;為解決此問題,已有研究使用向量表示單字,表明類神經網路架構的語言模型在各種任務上表現優於 N-gram,且能應用於 NLP 任務,如詞性標註、實體識別、語意角色識別,或者是後端的推薦系統應用。
在向量表示的單字中,一般會期待相似詞會傾向聚集在一起,然而研究表明單字可以擁有多重的相似度 (multiple degrees of similarity),尤其在屈折語 (inflectional languages) 中有明顯差異 (詞可能有不同的詞尾變化來表示性別、數、格等語法功能),例如 cars 不僅具有 car 的意義,也具有複數 s 的意義。
在這之外,驚人的發現簡單代數操作能處理出詞的相對意義,例如
$$ \begin{align*} \text{vector} (\text{king}) - \text{vector} (\text{man}) + \text{vector} (\text{woman}) \approx \text{vector} (\text{queen}) \end{align*} $$或者是
$$ \begin{align*} \text{vector} (\text{apple}) - \text{vector} (\text{apples}) \approx \text{vector} (\text{car}) - \text{vector} (\text{cars}) \end{align*} $$複雜度
類神經網路架構有更大運算需求,因此他們提倡不須使用過度複雜的模型,因此定義了訓練複雜度:
$$ \begin{align*} O = E \times T \times Q \end{align*} $$其中 $E$ 是訓練迭代次數 (epochs),即模型需訓練資料集的次數,一般選擇 3 ~ 50;$T$ 是訓練集內含的單字量;$Q$ 是根據模型設計所需的複雜度。
這邊不詳細描述各模型 $Q$ 的數值。簡單來說,早期的非線性類神經網路架構,如 feedforward neural net language model (NNLM) 與 recurrent neural net language model (RNNLM),其 $Q$ 都非常大;也就是訓練成成本極高。
因此他們轉而開發 log-linear 的模型,也就是 continuous bag-of-words (CBOW) 與 skip-gram。
結果評估
以往的評估方式是選定單字後,列出他們最相近的向量,以直接評估效益如何。但這忽視了文字擁有多重相似意義,因此他們設計了另一種比對方式,例如 big 與 biggest 的關係之於 small 與 smallest,即
$$ \begin{align*} \text{vector} (\text{big}) - \text{vector} (\text{biggest}) + \text{vector} (\text{small}) \overset{?}{=} \text{vector} (\text{smallest}) \end{align*} $$以此方式設計了上萬種的語義和句法問題,例如選擇美國的 68 個大城市與他們所屬的州。
他們選用 Google News 作為訓練集,大約 $10^{11}$ 總字量,訓練選用常用的 $10^{6}$ 個單字。CBOW 與 skip-gram 選擇 window = 5,即考慮前後文的各 5 個單字來預測中心詞。其實驗結果顯示:
- 向量維度越高,答題正確率越高。
- 訓練資料量越多,答題正確率越高,
- skip-gram 答題正確率 CBOW 好,但 skip-gram 訓練所需時間較 CBOW 多 (在此實驗差了 3 倍)
- skip-gram 與 CBOW 答題正確率較 NNLM 好,且訓練時間也更少 (在此實驗差了 10 倍)
結論
要訓練高品質的 word to vector 可以使用簡單的模型架構實現,尤其在非常巨大的資料量下,NNLM 類型的模型訓練成本極高,且所需計算參數極多,使得難以精確計算出高維度的向量表達。
參考資料
Mikolov, T. (2013). Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781, 3781.
Learning Word Vectors for 157 Languages - fastText
Facebook 在 2018 年發開的預訓練的 word to vector 模型 fastText,使用 wiki 與 common crawl 上的資料,以 300 維度表示單詞,並支援 157 種語言。
Subword
在經典的 word to vector 中,不同的字尾或形態會被視同不同的單詞,例如 “cars” 與 “car”,而在變化性較高的語言中 (範例是芬蘭語) 較難處理,而現實中還會有罕見字,錯拚字等問題使得字詞變得更加難以處理。
fastText 使用的技術是 subword 技術,將文字拆分成 n-gram 模型,例如 where 會拆分成 <wh, whe, her, ere, re>,其中 < 與 > 標示字頭與字尾,即:
使得單字的向量表達:
$$ \begin{align*} v_{w} = \sum_{g \in G_w} v_g \end{align*} $$在 CBOW 的架構中是給定中心詞 $w_0$,預測前後前後 $C$ 個字,即 $\\{ w_{-C}, \cdots, w_{-1}, w_1, \cdots, w_C \\}$,使得向量表示為:
$$ \begin{align*} \bs h = \sum_{\substack{i = -C \\ i \ne 0}}^{i = C} v_{w_i} \end{align*} $$在 fastText 的設計中使用:
$$ \begin{align*} \bs h = \sum_{\substack{i = -C \\ i \ne 0}}^{i = C} z_i v_{w_i} \end{align*} $$其中 $z_i$ 為位置權重,意義上是離中心詞越遠,其權重越低。
結論
能處理字母體系中的沒見過的詞 (OOV, Out of Vocabulary),使字被拆分成更加細小的語言結構,因而部分能處理錯拼字問題。另一部分能減少字彙表,即能用更少的字彙表容納相同的資料集。
參考資料
E. Grave*, P. Bojanowski*, P. Gupta, A. Joulin, T. Mikolov, Learning Word Vectors for 157 Languages
總結
參數設定
就論文中常見設定與網路上推薦的設定,參數設定會有幾個建議
- 向量維度: 100 ~ 300
- 取決於樣本數量大小,樣本越多則維度可以越高,以獲取更加細緻的語言信息;但維度越高,計算需求、overfitting 風險也越高。
- 窗口 (window): 5 ~ 10
- 窗口決定要看前後文的數量,窗口越大則能捕捉更加全局的資訊,過大則會使單個字的意義失真。
- 迭代次數 (epochs): 5 ~ 10
- 學習率 (learning rate): 0.025 ~ 0.0001
- 較高學習率能在模型初期帶來更大的參數更新,但也增加的不穩定的風險。
- 線性衰減降低學習率,隨著迭代次數降低學習率。
向量意義
任何 word to vector 的向量,在某個維度表示為正或負,並沒有很強的意義,向量會從原點向任意維度發散。
Survey
Li, Y., & Yang, T. (2018). Word embedding for understanding natural language: a survey. Guide to big data applications, 83-104.