
軟體生態系 (Software Ecosystems)
簡介
軟體生態系 (Software Ecosystems) 是指軟體、用戶與開發者社群的綜合體,並描述各方關係之間的利害關係,目的是要創造一個可持續的生態體系
軟體生態系組成
- 核心平台: 軟體生態圈的中心,可以是作業系統 (Linux)、程式語言 (Python、R、Julia)、平台 (Android、iOS) 或是框架 (Hugo)
- 擴展功能: 為核心平台開發的各式功能、套件
- 開發者社群: 開發和維護生態系的成員,可能是獨立開發者或公司,為環境提供更多擴展性,例如 GitHub 的開發者社群
- 用戶: 生態系中最終的用戶,提出需求、反饋與意見。
特點
網絡效應 (Network Effects): 生態系用戶增加,生態系的價值隨之增加,例如社群軟體的用戶少,能提供的體驗有限
人增加 -> 開發者增加 -> 軟體增加 -> 選擇增加 -> 用戶增加
互相依存: 生態系內部互相依存,生態系內變化會有連鎖反應,例如核心平台更新會導致所有附加功能需要調整兼容性
協同創新: 生態系內部協作促進創新,共享知識和資源來創新,從而提高生態系的價值
生態系治理: 生態系需制定管理的規則,確保持續穩定和發展
市場動態: 生態系內有眾多參與者,市場動態變得複雜。例如彼此可以同是競爭與合作關係
未來趨勢
- AI 和自動化: AI 協作成為趨勢,當今不少軟體正在嘗試在引入 AI 以實現自動化,壓縮了套件的生存空間
- 開放性: 生態系有逐漸變開放的趨勢,導致更多創新與競爭,用戶的選擇也能增加
- 持續性: 沒人願意使用隨時會倒的軟體
開源軟體
使用第三方開源軟體 (package, 套件) 能降低開發門檻且加速開發,卻帶有相對應的風險
- 不保證正確性
- 引入某套件後卻未使用
- 套件之間錯綜複雜的互相依賴
- 切換至不同語言或平台上的泛化能力
開源軟體開發
開源軟體中會遇到的數個問題
- 一個套件的負責到哪?
- 如何防範有問題的程式碼被加入套件中
研究這些套件的性質,是甚麼使他們熱門與成功的,分 4 步
- 規劃要挖掘哪些資訊
- 定義組件及其依賴關係
- 界定邊界與完整性
- 數據分析和視覺化
依賴關係
套件們的依賴圖
這張圖來源自 https://docs.github.com/en/code-security/supply-chain-security/understanding-your-software-supply-chain/about-the-dependency-graph,分析了 Python 幾個知名套件的依賴關係

Libraries.io 能分析套件的潛在風險、評估程式碼、評估貢獻等功能。
貢獻
給定某個時間下,例如某套件的依賴 - 貢獻圖為
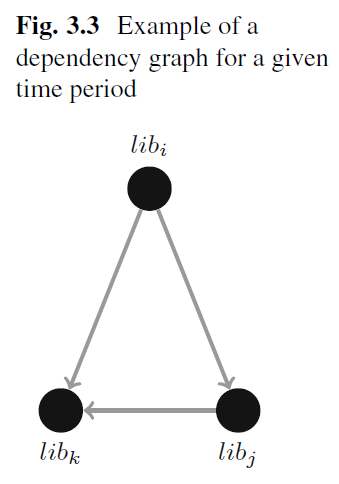
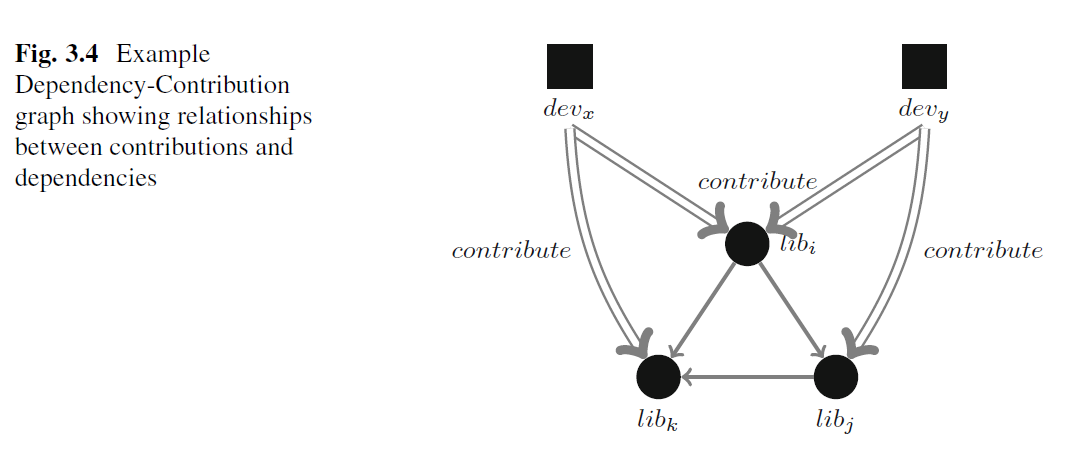
找出貢獻會有幾個問題
- 一人多重帳號,但 Github 使用多重身分驗證,使得多帳號的變得較麻煩
- 機器人 (bot) 貢獻,使用自動化更新依賴 (auto update dependency) 會使得貢獻圖加入很多不必要的噪音
- 並非所有開發者的行為都是公開的,有些套件的隱私設定會隱藏
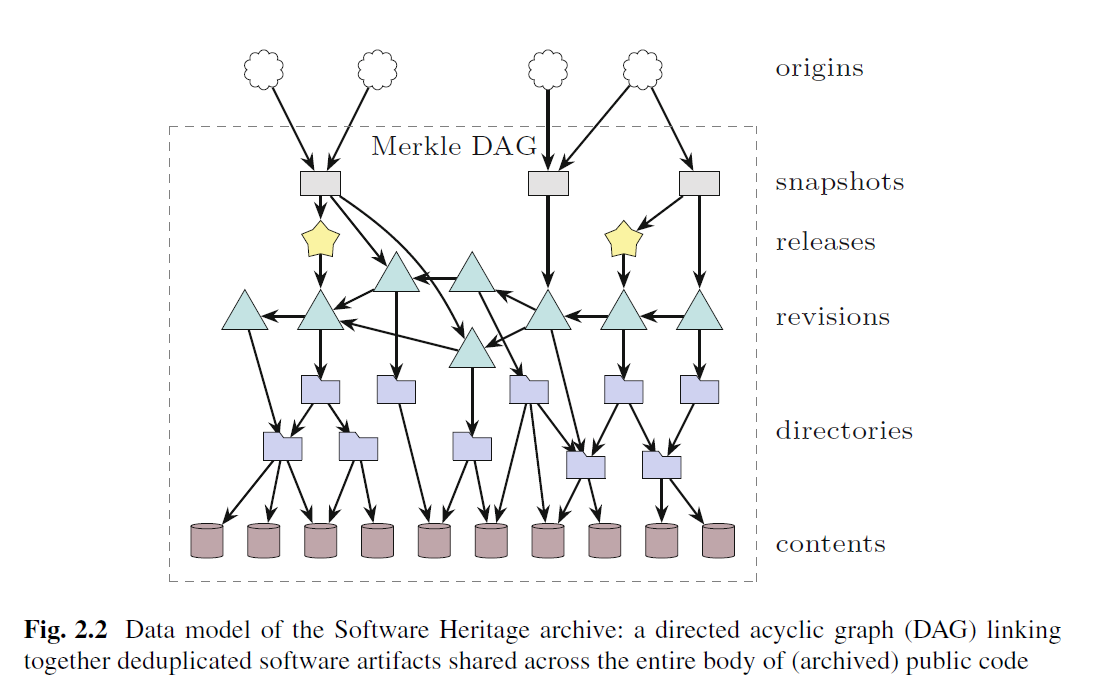
Software Heritage
許多早期軟體因無保存而消失,Software Heritage 收集原始碼的方式來保存軟體,將原始碼與發開歷史儲存在統一的格式 (Merkle Directed Acyclic Graph) 中;並表示軟體是重要的文化遺產,人類沒有能力承擔失去它的風險。
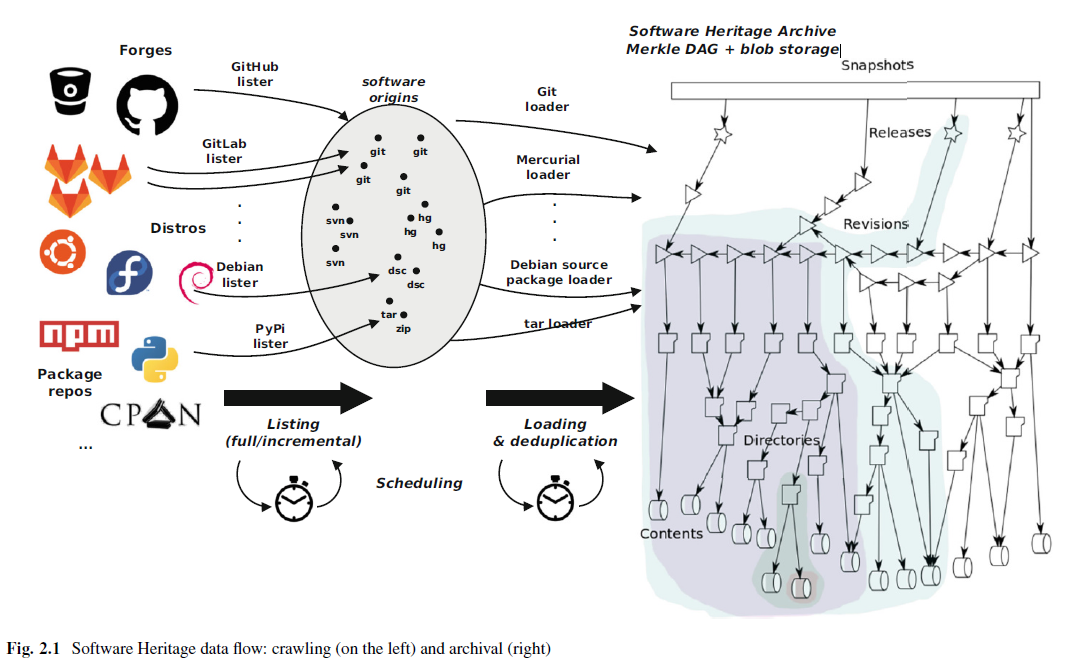
SECO-ASSIST 則是在解決彈性的軟體推薦系統、分析演化與社會互動。
定義邊界和複雜度 (Boundaries and Completeness)
定義依賴關係,並不能僅依靠設定檔提供的依賴關係,有可能宣告依賴某套件但完全沒使用,應以程式碼為主的方式檢查依賴關係
研究套件生態系的邊界來研究開發者社群,其中的邊界
- 技術邊界:不同套件可能基於不同程式語言
- 社群邊界:不同社群的會有各自的文化,例如 Minecraft 的 mod 管理器就有 Forge 和 Fabric
- 組織邊界:不同套件可能由特定公司、組織或基金會管理
一個套件缺乏互動不表示失敗,例如高度依賴的的套件且完整性足夠
研究套件包的完整依賴關係可能過於複雜,適度的縮減研究範圍是必要的
- 依賴關係可能會隨時間改變,因此可以指定某個時間點的套件
- 切分每 3 個月的版本,而非所有版本
- 部分採樣,可能只要提及一套件,其子套件就非常龐大,例如限制深度為 3 層
可能的觀察關係
- 休眠計畫並不一定意味著它不活躍,使用依賴者和依賴性的數量,作為項目在生態系中重要性的更好指標。
- 不應僅依靠程式語言來定義子社群。使用程式語言的通用套件管理器是區分邊界的更有效的經驗法則。
- 避免隨機抽樣,抽樣應根據研究目標進行定制,考慮適當的時間窗口等因素或關注組成部分的特定屬性(例如,最受依賴的、最受歡迎的、貢獻最大的)。
Model Driven Engineering
機器學習的能找出事物之間的關聯,那我們也能透過 Github 上的 “issue” 與 “update” 中找尋出問題與假的關係,並做出以下應用
- 模型助手: 在建立模型時協助用戶提高效率和精確性,或者自動化完成常見任務。例如自動補全、錯誤檢測、模型優化建議
- 分類: 將開發過程的資源自動分類,協助開發者找到相應的資源、優化管理
- 重構: 在不改變架構的前提下改善內部結構,增加可維護性與易讀性
- 修復: 自動糾正錯誤或不一致性,使其符合一致的規範,例如語法糾正、自動識別輸入物件是否合法
- 轉換開發: 更換程式語言或框架後,透過轉換規則自動化切換
參考資料
- MENS, Tom; DE ROOVER, Coen; CLEVE, Anthony (ed.). Software Ecosystems: Tooling and Analytics. Springer Nature, 2023.