推薦系統
引言
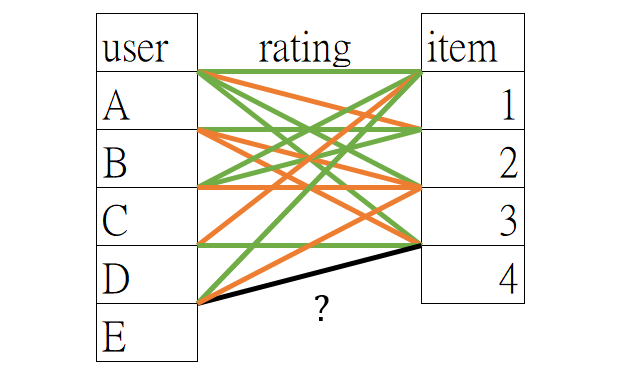
推薦系統的目標是「預測用戶 (user) 對某物件 (item) 的喜好」,最簡易的推薦方式不外乎隨機推薦、熱門推薦,但效益不好。目前主流的推薦系統可分為
- Content Based Filtering: 基於 特徵 feature 推薦
- Collaborative Filtering: 基於 共通喜好 rating 推薦
- Memory Based: 喜好相似 user 或 item
- user based
- item based
- Model Based: 建模描述 user 和 item 的相似
- Neural Networks
- Graph Networks
- Deep Learging
- Memory Based: 喜好相似 user 或 item
- Hybrid Approach: 混合法
- Two Tower Embedding: 一塔表示 use,另一塔表示 item
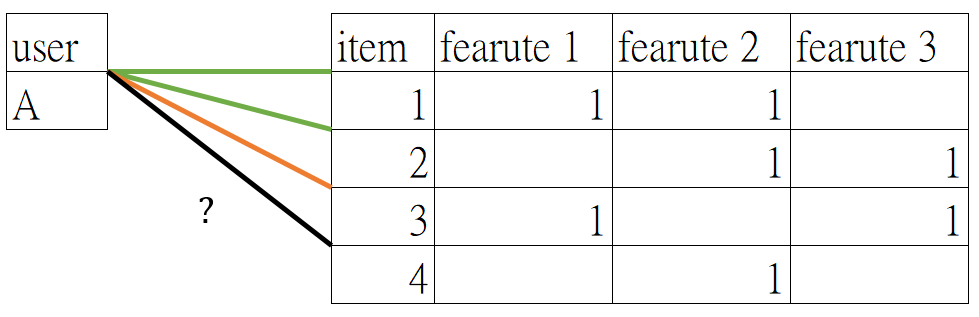
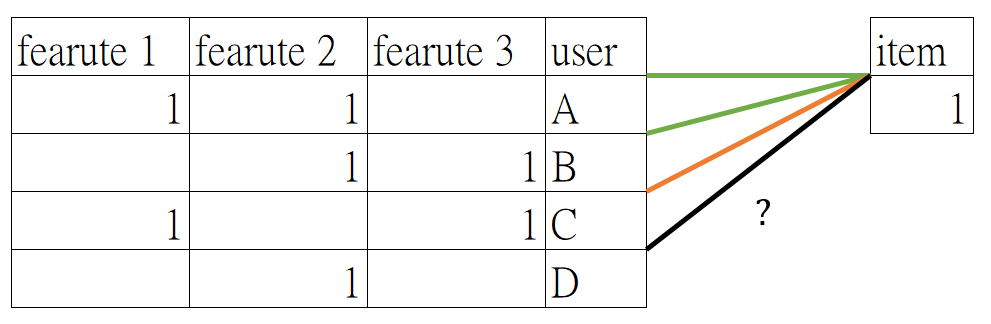
Content Based Filtering (CB)
基於 特徵推薦「甚麼產品跟這個產品很像」
| 優點 | 缺點 |
|---|---|
| 不需要其他使用者的評分,僅需要 user 歷史紀錄 新 item 只要有相同特徵就能被推薦 | 需要詳細 item 特徵 |
| 較廣度 item 的探索性 | 較沒有深度 item 的探索性 |
| 沒有同溫層效應 | 不能捕捉到 user 的興趣演變 |
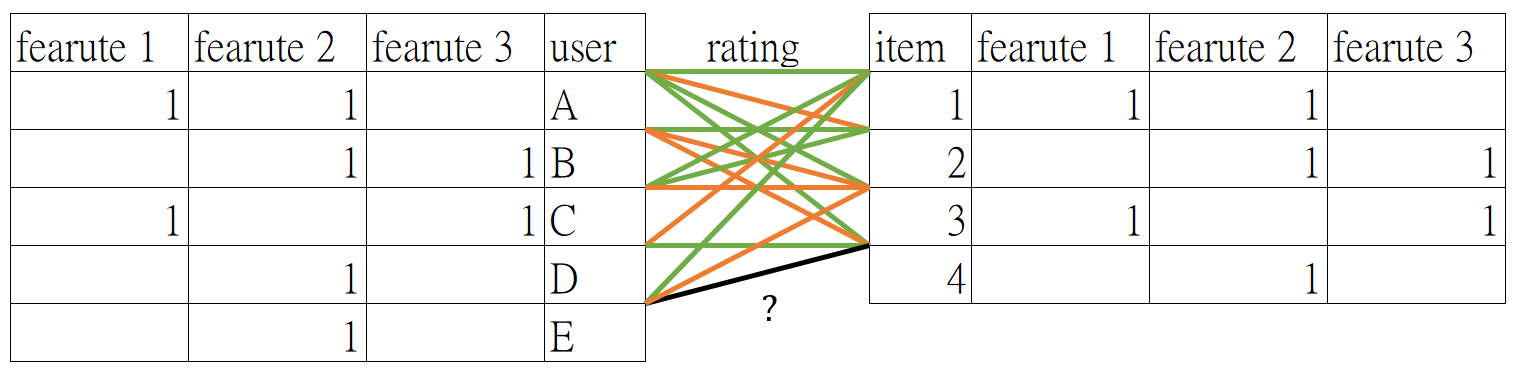
Collaborative Filtering (CF)
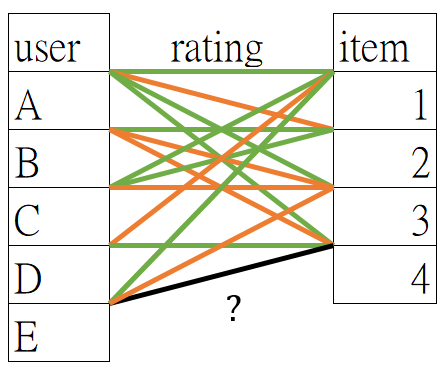
基於 users 共同喜好推薦「買了這東西的人也買了什麼?」,推薦分為2種
| 優點 | 缺點 |
|---|---|
| 不需要 item 有深入特徵,僅需要 user 的評分 | cold start: 需要靠 user 行為確認 item 相似度 對新 user / item 不友善 |
| 較深度 item 的探索性 | 較沒有廣度 item 的探索性 |
| 捕捉到 user 的興趣演變 | 同溫層: 對立觀點相似度低,算法不推薦 |
User Based
根據 user 的資訊 (評價、購買紀錄),計算 user 之間的相似度,把相似 user 也喜好的 item 推薦給其他 user,常推薦熱門 item
Item Based
根據 user 喜歡 item 1 也喜歡 item 2, 3, 4 的機率,計算 item 之間的相似度,把相似的 item 推薦給其他 user,常推薦 long-tail item (購買聲望不高,但持續購買)
Networks
Neural Networks
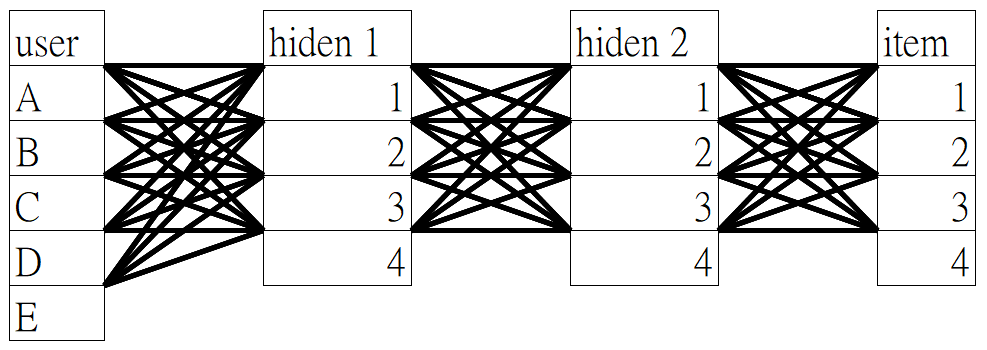
Graph Networks
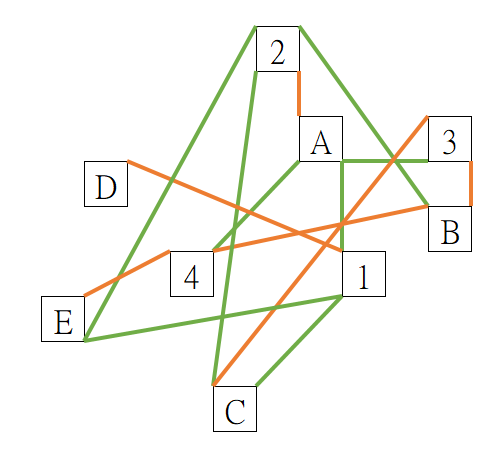
也能考慮 Latent Dirichlet Allocation (LDA)
Hybrid Approach
結合不同推薦方法,降低單一方法的缺點,例如 Two Tower Embedding 建構兩座獨立的塔,一座塔描述 item ,可能使用 content based filtering;另一座塔描述 user,可能使用 collaborative filtering
Two Tower Embedding
建構兩座塔,用於刻劃 user 和 item,常用 deep learning、neural network 建構
- Query Tower $\bs \beta$: user 的特徵
- Candidate Tower $\bs x$: item 的特徵
例如某 user 的特徵可能被刻劃成 $\bs \beta = (\contia{\beta}{p})^T$,其中
| 特徵 | 描述 | 數值 |
|---|---|---|
| $\beta_1$ | 數學喜好 | 1 |
| $\beta_2$ | 爆炸喜好 | 0.9 |
| $\vdots$ | $\vdots$ | $\vdots$ |
| $\beta_p$ | 體育喜好 | -0.6 |
某影片 item 的特徵則寫成 $\bs x = (\contia{x}{p})^T$,其中
| 特徵 | 描述 | 數值 |
|---|---|---|
| $x_1$ | 有數學 | 1 |
| $x_2$ | 有爆炸 | 1 |
| $\vdots$ | $\vdots$ | $\vdots$ |
| $x_p$ | 無體育 | 0 |
藉由捕捉特徵把 user 與 item 向量化,用此可以描述 user-user / user-item / item-item 的距離關係,常用的方式有
- Inner product: 數值越大,相似度越高 $$ \begin{align*} \bs x \cdot \bs \beta = \sum_{i = 1}^{p} x_i \beta_i \end{align*} $$
- Euclidean distance: 數值越大,相似度越低 $$ \begin{align*} \norm{\bs x - \bs \beta}\_2 = \sqrt{ \sum_{i = 1}^{p} (x_i - \beta_i)^2 } \end{align*} $$
因此無論對 user 需要推薦 item,或是 item 需要找到目標 user,都能藉由此方式推薦。例如以 inner product 作為距離關係,在考慮推薦 user 何種 item 時,僅需在對 item 的 inner product 排序即可。
挑戰: 沒有歷史數據導致
- novel: 新 item,沒 $\bs x$
- cold start: 新 user ,沒 $\beta$
Augmentations Contrastive Learning (ACL)
Sparse 導致建模問題
- feature sparsity: user 或 item 特徵太少
- interaction sparsity: 擁有某特徵的 user 或 item 太少
解法:
- data augmentations: 相近組成一組,減輕 feature sparsity
- contrastive learning: 分辨相似/不相似,減輕 interaction sparsity