主成分分析 (Principal Component Analysis, PCA)
簡介
多變量分析中的經典方法,主成分分析 (Principal Component Analysis, PCA),一種基於正交轉換 (orthogonal transformation) 的技術,在盡可能保留資料特徵的前提下降低維度,常用於
- 資料降維
- 視覺化
- 處理共線性問題
線性代數工具
在開始介紹 PCA 前,先介紹幾個線性代數工具。
Pythagorean Theorem
高維度空間的畢氏定理,我們會以正交 (orthogonal) 稱呼高維度的「垂直」關係,其實就是二維度的垂直概念推廣,定義為兩個向量 $x, y \in \bb R^p$ 滿足 $x^T y = \bs 0$,則稱 $x$ 與 $y$ 正交。定義向量 $\bs x$ 長度為 $\norm{x}^2 = x^T x$。
給定兩個向量 $x, y \in \bb R^p$,若其正交,則
$$ \begin{align*} \norm{x + y}^2 & = (x + y)^T (x + y) \\ & = x^T x + 2 (x^T y) + y^T y \\ & = \norm{x}^2 + \norm{y}^2 \end{align*} $$這也能推廣到投影向量上,令 $z = (x^T y) y$ 為 $x$ 往向量 $y$ 上的投影向量,且 $y$ 為單位向量 ($y^T y = 1$),則 $z$ 與 $x - z$ 為正交,即
$$ \begin{align*} z^T (x - z) & = z^T x - z^T z \\ & = (x^T y)^2 - (x^T y)^2 (y^T y) \\ & = 0 \end{align*} $$因 $z$ 與 $x - z$ 正交,因此有 $\norm{z + (x - z)}^2 = \norm{z}^2 + \norm{x - z}^2$,移項後可得
$$ \begin{align*} \norm{x - z}^2 = \norm{x}^2 - \norm{z}^2 \end{align*} $$其中 $z = (x^T y) y$ 且 $y$ 為單位向量 ($y^T y = 1$)。
Rayleigh Quotient
見 Rayleigh quotient。若 $A \in \mathbb R^{p \times p}$ 是對稱 (symmetric) 矩陣,則
$$ \begin{align*} \max_{x \in \mathbb R^p} x^T A x = \lambda_1 \geq \lambda_2 \geq \cdots \geq \lambda_p = \min_{x \in \mathbb R^p} x^T A x \end{align*} $$其中 $\lambda_1, \lambda_2, \cdots, \lambda_p$ 是 $A$ 的特徵值。令 $v_i$ 為對應 $\lambda_i$ 的單位特徵向量,則
$$ \begin{align*} v_1 & = \argmax_{x^T x = 1} x^T A x \\ v_2 & = \argmax_{\substack{x^T x = 1 \\ x^T v_1 = 0}} x^T A x, \\ v_3 & = \argmax_{\substack{x^T x = 1 \\ x^T v_i = 0, \ i = 1, 2}} x^T A x, \\ & \quad \vdots \\ v_p & = \argmax_{\substack{x^T x = 1 \\ x^T v_i = 0, \ i = 1, 2, \cdots, p - 1}} x^T A x \end{align*} $$解釋為
- $v_1$ 是 $\lambda_1$ 對應的特徵向量
- $v_2$ 是 $\lambda_2$ 對應的特徵向量,且 $v_2$ 與 $v_1$ 正交
- $v_3$ 是 $\lambda_3$ 對應的特徵向量,且 $v_3$ 與 $v_1$, $v_2$ 正交
- $\vdots$
- $v_p$ 是 $\lambda_p$ 對應的特徵向量,且 $v_p$ 與 $\contia{v}{p - 1}$ 正交
為了方便起見,以 $\lambda_i$ 表示 $A$ 當中第 $i$ 大的特徵值 ($\lambda_1$ 表示最大),$v_i$ 為對應 $\lambda_i$ 的單位特徵向量。
$$ \begin{align*} E_\lambda (A, i) & = \lambda_i \\ E_v (A, i) & = v_i \\ \end{align*} $$Data Decomposition
變數降維
給定一個高維度資料 $X \in \bb R^{n \times p}$,令
$$ \begin{align*} X_i & = (x_{i1}, X_{i2}, \cdots, X_{ip})^T \in \bb R^{p} \\ X_{[j]} & = (x_{1j}, X_{2j}, \cdots, X_{nj})^T \in \bb R^{n} \end{align*} $$其中 $X_i$ 為列向量,作為樣本;$X_{[j]}$ 為行向量,作為變數。
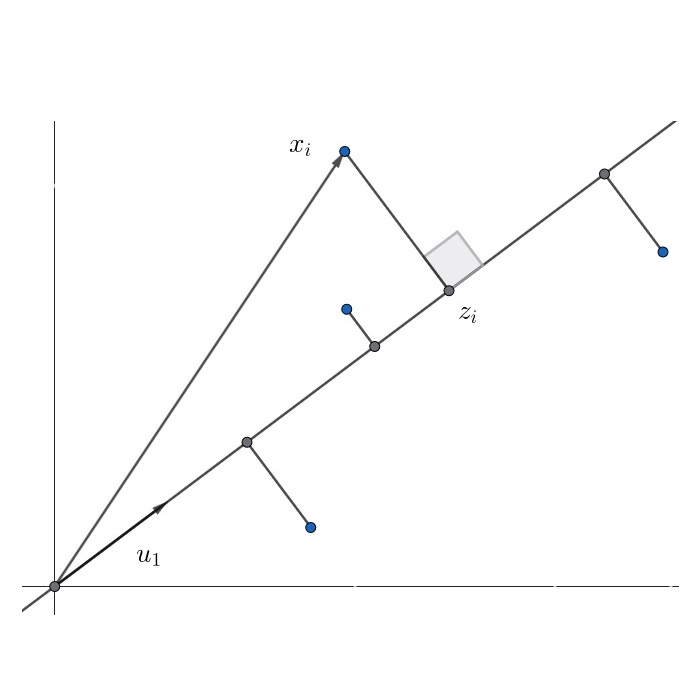
我們想找到一條通過原點的直線,使得資料點 $x_i$ 投影到線上後能損失最少資訊;換句話說,找到一個單位向量 $u_1 \in \bb R^p$,使原始資料 $x_i$ 往 $u_1$ 上的投影點 $z_i$ 的距離越短越好。
令 $p_i \in \bb R$ 為 $x_i$ 往 $u_1$ 上的投影長度,$z_i \in \bb R^p$ 為 $x_i$ 往 $u_1$ 上的投影向量。
$$ \begin{align*} p_i & = x_i^T u_1 \\ z_i & = p_i u_1 = (x_i^T u_1) u_1 \end{align*} $$原始資料 $x_i$ 經投影後至 $z_i$,其損失資訊量為 $x_i - z_i$,而最佳投影向量就是以最小損失量為目標。
$$ \begin{align*} u_1 & = \argmin_{u_1^T u_1 = 1} \sum_{i = 1}^{n} \norm{ x_i - z_i }^2 \\ & = \argmin_{u_1^T u_1 = 1} \sum_{i = 1}^{n} \norm{ x_i }^2 - \norm{ z_i }^2 && \text{(Pythagorean Theorem)} \\ & = \argmin_{u_1^T u_1 = 1} \sum_{i = 1}^{n} - \norm{ z_i }^2 \\ & = \argmax_{u_1^T u_1 = 1} \sum_{i = 1}^{n} \norm{ z_i }^2 \\ & = \argmax_{u_1^T u_1 = 1} \sum_{i = 1}^{n} \norm{ x_i^T u_1 }^2 && (u_1^T u_1 = 1) \\ & = \argmax_{u_1^T u_1 = 1} u_1^T (X^T X) u_1 \\ & = E_v (X^T X, 1) && (\text{Rayleigh Quotient}) \end{align*} $$其中幾個關鍵步驟的解釋,最小化資訊差 $\norm{ x_i - z_i }^2$ 等價於最大化投影長度 $\norm{ x_i^T u_1 }^2 = p_i^2$,其解為使 $u_1^T (X^T X) u_1$ 最大化的 $u_1$,根據 Rayleigh Quotient 可知,$u_1$ 為 $X^T X$ 中最大特徵值 $\lambda_1$ 所對應的特徵向量。
投影完第一個維度後,還能繼續再對下一個方向降維,我們希望找到另一個單位向量 $u_2$,在 $u_2$ 與 $u_1$ 正交的條件下最小化資訊差
$$ \begin{align*} u_2 & = \argmin_{\substack{u_2^T u_2 = 1 \\ u_2^T u_1 = 0}} \sum_{i = 1}^{n} \norm{ x_i - z_i }^2 && (z_i = (x_i^T u_2) u_2) \\ & = \argmax_{\substack{u_2^T u_2 = 1 \\ u_2^T u_1 = 0}} u_2^T (X^T X) u_2 \\ & = E_v (X^T X, 2) && (\text{Rayleigh Quotient}) \end{align*} $$再次根據 Rayleigh Quotient 可知,$u_2$ 為 $X^T X$ 中第 $2$ 大的特徵值 $\lambda_2$ 所對應的特徵向量。接著重複這個步驟,將維度降低至 $q$ ($q \leq p$) 維度,其 $v_q$ 與 $\contia{v}{q - 1}$ 皆互相正交的前提下最小化資訊差,$u_q$ 為 $X^T X$ 中第 $q$ 大的特徵值 $\lambda_q$ 所對應的特徵向量。
$$ \begin{align*} u_q = E_v (X^T X, q) \end{align*} $$最後,降維後的投影點即為 $x_i$ 分別往 $\contia{u}{q}$ 投影的投影向量,令 $U \in \bb R^{p \times q}$ 為
$$ \begin{align*} U = (u_1 | u_2 | \cdots | u_q) = \begin{pmatrix} u_{11} & u_{21} & \cdots & u_{q1} \\ u_{12} & u_{22} & \cdots & u_{q2} \\ \vdots & \vdots & \ddots & \vdots \\ u_{1p} & u_{2p} & \cdots & u_{qp} \\ \end{pmatrix} \end{align*} $$使得新的投影座標為
$$ \begin{align*} Z = X_{n \times p} U_{p \times q} \in \bb R^{n \times q} \end{align*} $$最終,$n$ 個 $p$ 維度的資料降維至 $q$ ($q \leq p$) 維度,且各個新的維度彼此是正交的。
標準化前提
中心化
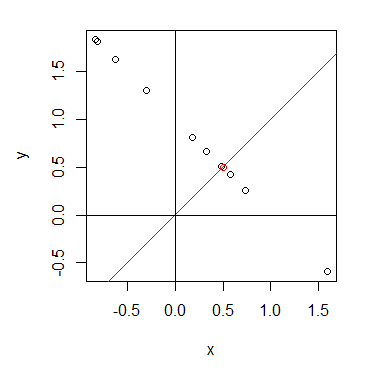
在投影時 $u_1$ 會通過原點,所以必須先將資料的中心放在原點,或者說中心化。若不將資料中心化,如下範例,原始資料是帶有一些資訊的 (線性關係),但投影後的點全部重疊在一個點上,使得資訊幾乎全部消失了。
標準化
若資料間的量級差異過大,如下範例,身高的尺度大約比年紀多了10倍,若要最小化變異數,PCA 會傾向於先最小化身高的變異數,但或許身高所攜帶的資訊並沒有比年紀多。
| 身高 (公分) | 年紀 (歲) |
|---|---|
| 180 | 20 |
| 160 | 22 |
| 175 | 26 |
| 170 | 18 |
| … | … |
注意:任何談及最小化的手法,都需要特別注意是否需要標準化,因為紀錄單位的量級差距並不會提供更多資訊,例如以公分紀錄比公尺紀錄多了100倍,但攜帶的資訊量卻是一樣多的。
樣本降維
前面是將資料以變數方向從 $p$ 維降低至 $q$ 維,而降維的技術也能以樣本方向從 $n$ 維降低至 $m$ 維,僅需將資料轉置。如樣本方向的降維
$$ \begin{align*} v_1 & = \argmin_{v_1^T v_1 = 1} \sum_{j = 1}^{p} \norm{ x_{[j]} - z_{[j]} }^2 && (z_{[j]} = (x_{[j]}^T v_1) v_1) \\ & = \argmax_{v_1^T v_1 = 1} v_1^T (X X^T) v_1 \\ & = E_v (X X^T, 1) && (\text{Rayleigh Quotient}) \end{align*} $$其中 $v_1$ 最佳的向量是 $X X^T$ 中第 $1$ 大的特徵值 $\lambda_1$ 所對應的特徵向量。同理,其餘維度 $m$ ($m \leq n$) 的向量為
$$ \begin{align*} v_m & = E_v (X X^T, m) \end{align*} $$最後,降維後的投影點即為 $x_i$ 分別往 $\contia{v}{m}$ 投影的投影向量,令 $V \in \bb R^{n \times m}$ 為
$$ \begin{align*} V = (v_1 | v_2 | \cdots | v_m) = \begin{pmatrix} v_{11} & v_{21} & \cdots & v_{m1} \\ v_{12} & v_{22} & \cdots & v_{m2} \\ \vdots & \vdots & \ddots & \vdots \\ v_{1n} & v_{2n} & \cdots & v_{mn} \\ \end{pmatrix} \end{align*} $$新的投影座標為
$$ \begin{align*} W = X^T_{p \times n} V_{n \times m} \in \bb R^{p \times m} \end{align*} $$Duality Relations
這個段落討論 $u_q$ 與 $v_m$ 向量之間的關聯。令 $r = \rank (X) \leq \min (n, p)$,則 $r = \rank (X X^T) = \rank (X^T X)$,且 $X^T X$ 與 $X X^T$ 擁有相同前 $r$ 大的特徵值。
對任意 $k \leq r$,擁有對偶性質
$$ \begin{align*} v_k & = \frac{1}{\sqrt{\lambda_k}} X u_k \\ u_k & = \frac{1}{\sqrt{\lambda_k}} X^T v_k \end{align*} $$其新的投影向量也具有對偶性質
$$ \begin{align*} Z_{[k]} & = \sqrt{\lambda_k} v_k \\ W_{[k]} & = \sqrt{\lambda_k} u_k \end{align*} $$因此計算時僅需考慮維度較低的進行投影。例如 $n > p$ 時,計算 $u$ 時僅需在 $p \times p$ 的矩陣中計算特徵值,另一側的 $v$ 僅需透過對偶性質即可得出。
證明
對任意 $k \leq r$,兩個方向的特徵向量滿足
$$ \begin{align*} (X^T X) u_k & = \lambda_k u_k \\ (X X^T) v_k & = \lambda_k v_k \\ \end{align*} $$從 $u_k$ 的方向開始,考慮
$$ \begin{align*} (X X^T) (X u_k) & = X [(X^T X) u_k] = \lambda_k (X u_k) \end{align*} $$此時能看出 $X u_k$ 為 $X X^T$ 第 $k$ 大特徵值所對應的特徵向量,同時已知 $v_k$ 也是 $X X^T$ 第 $k$ 大特徵值所對應的特徵向量,因此存在某個常數 $a_k$ 使得
$$ \begin{align*} v_k = a_k X u_k \end{align*} $$因 $u_k$ 與 $v_k$ 皆為單位向量,得出
$$ \begin{align*} 1 & = v_k^T v_k && (\norm{v_k}^2 = 1) \\ & = a_k^2 u_k^T X^T X u_k && (v_k = a_k X u_k) \\ & = a_k^2 \lambda_k u_k^T u_k && (X^T X u_k = \lambda_k u_k) \\ & = a_k^2 \lambda_k && (\norm{u_k}^2 = 1) \end{align*} $$解出 $a_k = 1 / \sqrt{\lambda_k}$,同理也能解出
$$ \begin{align*} v_k & = \frac{1}{\sqrt{\lambda_k}} X u_k \\ u_k & = \frac{1}{\sqrt{\lambda_k}} X^T v_k \end{align*} $$其新的投影向量也具有對偶性質
$$ \begin{align*} Z_{[k]} & = X u_k \\ & = \frac{1}{\sqrt{\lambda_k}} X X^T v_k && \left( u_k = \frac{1}{\sqrt{\lambda_k}} X^T v_k \right) \\ & = \sqrt{\lambda_k} v_k && ((X X^T) v_k = \lambda_k v_k) \end{align*} $$另一方向也同時滿足對偶性質
$$ \begin{align*} W_{[k]} = \sqrt{\lambda_k} u_k \end{align*} $$成分評估
這段將考慮什麼樣的投影為所謂的「表現好」。
資料降維時,以 $x_i$ 為原始資料具有所有「資訊」,$z_i = (x_i u_1)^T u_1$ 為投影點,並定義 $x_i - z_i$ 為所謂的「資料損失量」,因此 $z_i$ 可以理解為「留存資訊量」。又因 Duality Relations 的 $Z_{[k]} = \sqrt{\lambda_k} u_k$ 得知 $\lambda_k = \norm{Z_{[k]}}^2$,為投影後的「留存資訊量」,因此定義 $\lambda_k$ 為投影後的「第 $k$ 維度資訊量」。
考慮前 $k$ 維度的特徵值 $\lambda_1 \geq \lambda_2 \geq \cdots \geq \lambda_k$,以 $\sum_{i = 1}^{p} \lambda_i$ 作為「資訊總量」,而 $\sum_{i = 1}^{k} \lambda_i$ 為「前 $k$ 維度的資訊總量」,因此對於前 $k$ 維度的「解釋量」定義為
$$ \begin{align*} \tau_k = \frac{\sum_{i = 1}^{k} \lambda_j}{\sum_{i = 1}^{p} \lambda_j} \end{align*} $$故 $0 \leq \tau_1 \leq \tau_2 \leq \cdots \leq \tau_p = 1$。在實際問題中,常以保有 $80\%$ 解釋量的前提進行降維 ($\tau_k > 0.8$)。
R 語言程式範例
PCA 範例
用 R 語言和 iris 做演示,首先讀取資料。
data = iris
y_colname = "Species"
x_colnames = setdiff(names(data), y_colname)
其中的 prcomp 即為 PRincipal COMponent 的簡稱,center 與 scale. 是先將資料標準後再做 PCA。
pca = prcomp(data[x_colnames], center = TRUE, scale. = TRUE)
print(pca)
summary(pca)
其輸出為
Standard deviations (1, .., p=4):
[1] 1.7083611 0.9560494 0.3830886 0.1439265
Rotation (n x k) = (4 x 4):
PC1 PC2 PC3 PC4
Sepal.Length 0.5210659 -0.37741762 0.7195664 0.2612863
Sepal.Width -0.2693474 -0.92329566 -0.2443818 -0.1235096
Petal.Length 0.5804131 -0.02449161 -0.1421264 -0.8014492
Petal.Width 0.5648565 -0.06694199 -0.6342727 0.5235971
Importance of components:
PC1 PC2 PC3 PC4
Standard deviation 1.7084 0.9560 0.38309 0.14393
Proportion of Variance 0.7296 0.2285 0.03669 0.00518
Cumulative Proportion 0.7296 0.9581 0.99482 1.00000
解釋
| PC1 | PC2 | PC3 | PC4 | |
|---|---|---|---|---|
| Sepal.Length | $u_{11}$ | $u_2$ | $u_3$ | $u_4$ |
| Sepal.Width | $u_{12}$ | |||
| Petal.Length | $u_{13}$ | |||
| Petal.Width | $u_{14}$ |
| PC1 | PC2 | PC3 | PC4 | |
|---|---|---|---|---|
| Standard deviation | $\sqrt{\lambda_1}$ | $\sqrt{\lambda_2}$ | $\sqrt{\lambda_3}$ | $\sqrt{\lambda_4}$ |
| Proportion of Variance | $\dps \frac{\lambda_1}{\sum_{j = 1}^{p} \lambda_j}$ | $\dps \frac{\lambda_2}{\sum_{j = 1}^{p} \lambda_j}$ | $\dps \frac{\lambda_3}{\sum_{j = 1}^{p} \lambda_j}$ | $\dps \frac{\lambda_4}{\sum_{j = 1}^{p} \lambda_j}$ |
| Cumulative Proportion | $\tau_1$ | $\tau_2$ | $\tau_3$ | $\tau_4$ |
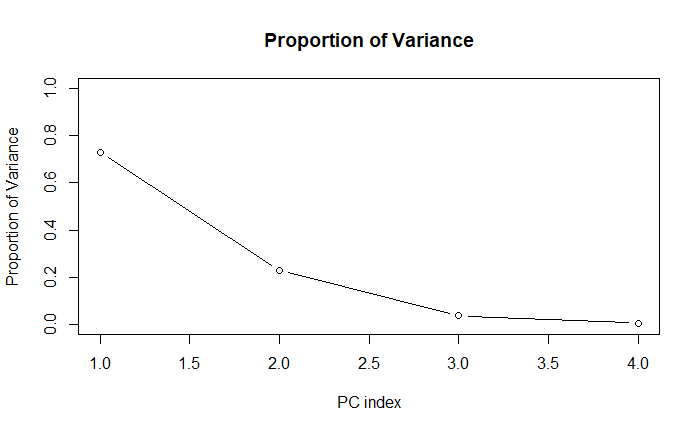
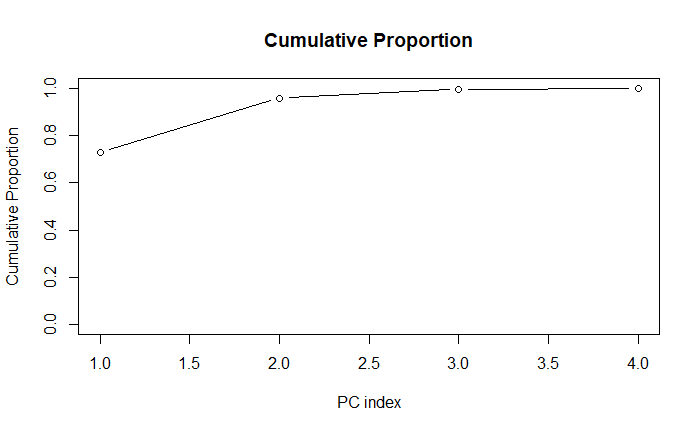
對解釋量做視覺化,簡單說的結論是「能用越少的 PC 達到越高的累積解釋量越好」。
pca.summary = summary(pca)
plot(pca.summary[['importance']]['Proportion of Variance', ],
type = "b",
xlab = "PC index",
ylab = "Proportion of Variance",
main = "Proportion of Variance",
ylim = c(0, 1))
plot(pca.summary[['importance']]['Cumulative Proportion', ],
type = "b",
xlab = "PC index",
ylab = "Cumulative Proportion",
main = "Cumulative Proportion",
ylim = c(0, 1))
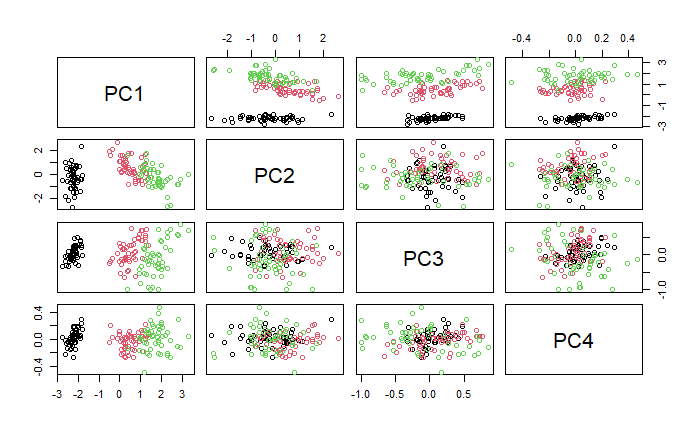
同樣的,能將資料投影到 PC 軸上進行視覺化。
pairs(pca$x, col = data$Species)
Data Explorer
用 DataExplorer 包能快速獲取資料包含 PCA 在內的基礎訊息
library(DataExplorer)
# config 設定將相關係數圖的圖例旋轉45度
create_report(iris,
config = configure_report(plot_correlation_args = list(theme_config = list(axis.text.x = element_text(angle = 45)))))
更多參考
更多 PCA 參考用法請見 蘋果品質二元分類機器學習
參考資料
Applied Multivariate Statistics Analysis, Hardle and Simar