類神經網路 (Neural Network)
類神經網路
神經元 (Neuron)
下圖所展示的是一個人造神經元 (Neuron) 結構,$\{ \contia{x}{K} \}$ 是輸入端,$\{ \contia{w}{K} \}$ 是權重 (weight) 也是模型要訓練的目標,$f$ 是連結函數 (link function),$\hat y$ 是輸出
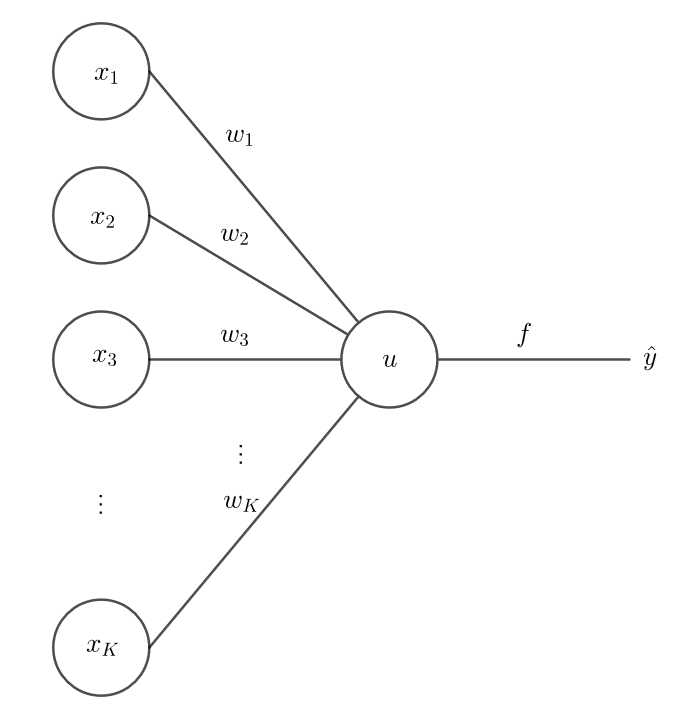
神經元會先計算向量和,其中 $x_0 = 1$ 作為截距項
$$ \begin{align*} u = \bs w^T \bs x = \sum_{i = 0}^{K} w_i x_i \end{align*} $$並透過連結函數 $f$ 將 $u$ 轉換成輸出
$$ \begin{align*} \hat y = f (u) \end{align*} $$此時一個神經元就像是一個廣義線性回歸,最後得選擇連結函數,若選擇 unit step function $f (u) = I \{ u > 0 \}$ 則是線性分類器;若選擇 logistic function 函數,則就是 Logistic Regression
Unit step function
最簡的選擇是 unit step function,選擇這種連結函數的神經元稱為感知器 (perceptron),一般設定0作為門檻,超過門檻才會能被感知
$$ \begin{align*} f (u) = I \{ u > 0 \} = \begin{cases} 1 & \text{if } u > 0 \\ 0 & \text{if } u \leq 0 \end{cases} \end{align*} $$並在梯度下降 (Gradient Descent) 時,透過下列方式迭代
$$ \begin{align*} \bs w^{(\text{new})} = \bs w^{(\text{old})} - \eta (y - \hat y) \bs x \end{align*} $$其中 $\eta > 0$ 是學習率 (learning rate),作為梯度下降時的步伐長度,越低的學習率越不容易錯過的全局最佳值,但容易陷入局部最佳值,且需迭代數量越大;越高的學習率越容易錯過的全局最佳值,但不容易陷入局部最佳值,且需迭代數量較小。$y$ 是真實的預測目標
使用 $u = 0$ 作為分類標準可能太硬,並且 unit step function 沒有較為良好的數學性質
Logistic Function
連結函數的另一種選擇是 logistic function,參見 Logistic Regression
$$ \begin{align*} \hat y = \sigma (u) = \frac{1}{1 + e^{-u}} \end{align*} $$這種函數有些良好的數學性質,$y$ 的範圍始終落在 $(0, 1)$ 區間內、$\sigma (u)$ 是可微的,在後續的梯度下降較方便,也有方便的運算性質
$$ \begin{align*} \sigma (-u) & = 1 - \sigma(u) \\ \frac{d \sigma (u)}{du} & = \sigma (u) \sigma (-u) = \sigma (u) [ 1 - \sigma (u) ] \end{align*} $$即
$$ \begin{align*} \frac{d \hat y}{du} = \hat y (1 - \hat y) \end{align*} $$在損失函數 (loss function) 的選擇方面,若選擇平方差作為損失函數
$$ \begin{align*} E = \frac{1}{2} (y - \hat y)^2 \end{align*} $$則損失函數的偏微分可以被寫為
$$ \begin{align*} \frac{\partial E}{\partial w_i} & = \frac{\partial E}{\partial \hat y} \frac{\partial \hat y}{\partial u} \frac{\partial u}{\partial w_i} \\ & = (y - \hat y) \hat y (1 - \hat y) x_i \end{align*} $$接著就能沿著梯度下降迭代出最佳值
$$ \begin{align*} \bs w^{(\text{new})} = \bs w^{(\text{old})} - \eta (y - \hat y) \hat y (1 - \hat y) \bs x \end{align*} $$反向傳播 (Back Propagation)
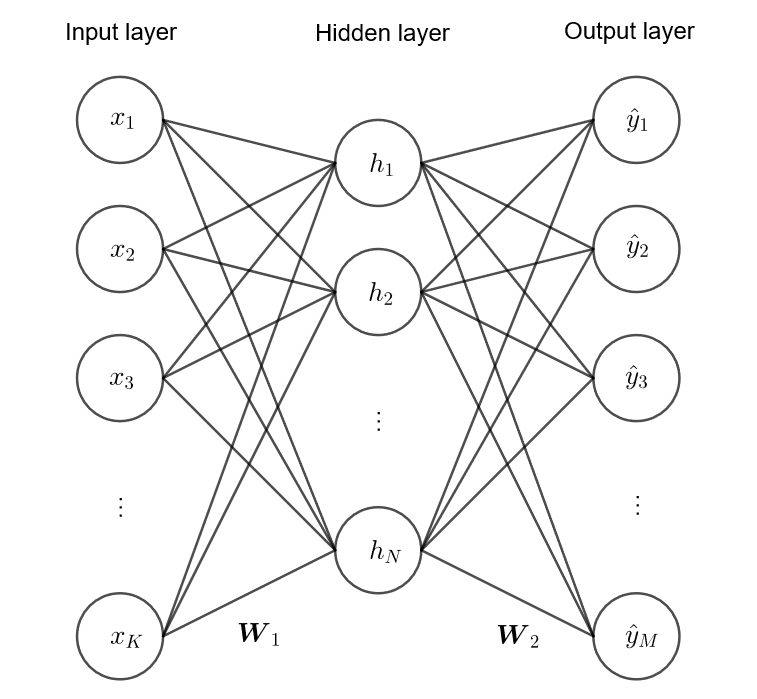
下圖展現的是一個多層類神經網路,$\bs x = (\contia{x}{K})$ 是輸入層,$\bs h = (\contia{h}{N})$ 是隱藏層 (hidden layer),$\hat {\bs y} = (\contia{\hat y}{M})$ 是輸出層;$\bs W_1 \in \bb R^{K \times N}$ 與 $\bs W_2 \in \bb R^{N \times M}$ 分別是輸入至隱藏層與隱藏至輸出層的權重
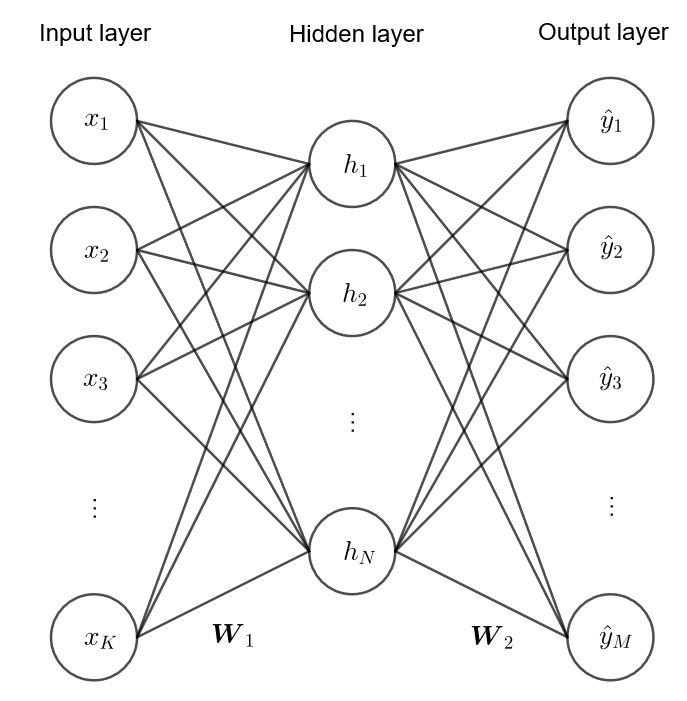
計算方式如下,其中 $\bs h = \sigma (\bs u_1)$ 表示 $h_1 = \sigma (u_{1, 1}), \cdots, h_N = \sigma (u_{1, N})$,$\hat {\bs y} = \sigma (\bs u_2)$ 同理
$$ \begin{align*} \bs u_1 & = \bs W_1^T \bs x, &&& \bs h & = \sigma (\bs u_1) \\ \bs u_2 & = \bs W_2^T \bs h, &&& \hat {\bs y} & = \sigma (\bs u_2) \\ \end{align*} $$給定 $\bs y \in \bb R^M$ 是真實的預測目標,若同樣以平方差作為損失函數,則迭代方式會如下討論
$$ \begin{align*} E = \frac{1}{2} \norm{\bs y - \hat {\bs y}}^2 = \frac{1}{2} (\bs y - \hat {\bs y})^T (\bs y - \hat {\bs y}) \end{align*} $$梯度下降
從最右側的權重 $\bs W_2$ 開始,接著一路向左調整權重 $\bs W_1$,若模型包含更多層的梯度也同理。對每層梯度下降時,得對損失函數做偏微分,分別對輸出、輸入最後再對權重偏微分的 3 步驟,就如同單個神經元的方式
第 1 層梯度下降
首先對輸出 $\hat y$ 進行偏微分
$$ \begin{align*} \frac{\partial E}{\partial \hat {\bs y}} & = \bs y - \hat {\bs y} \end{align*} $$接著對輸入 $\bs u_2$ 進行偏微分,其中 $\circ$ 是 Hadamard product,即逐項乘法,例如 $(A \circ B)_i = A_i B_i$。計算梯度後以 $\bs H_2$ 記錄,在下一層的迭代仍會用上
$$ \begin{align*} \frac{\partial E}{\partial \bs u_2} & = \frac{\partial E}{\partial \bs {\hat y}} \frac{\partial \bs {\hat y}}{\partial \bs u_2} = (\bs y - \hat {\bs y}) \circ \hat y \circ (\bs 1 - \hat {\bs y}) = \bs H_2 \end{align*} $$最後對權重 $\bs W_2$ 進行偏微分
$$ \begin{align*} \frac{\partial E}{\partial \bs W_2} & = \frac{\partial E}{\partial \bs u_2} \frac{\partial \bs u_2}{\partial \bs W_2} = \bs h \bs H_2^T = \bs G_2 \end{align*} $$第 2 層梯度下降
完成最右側的 $\bs W_2$ 梯度計算,向左移動處理 $\bs W_1$ 的梯度。首先對輸出 $\bs h$ 進行偏微分
$$ \begin{align*} \frac{\partial E}{\partial \bs h} & = \frac{\partial E}{\partial \bs u_2} \frac{\partial \bs u_2}{\partial \bs h} = \bs W_2 \bs H_2 \end{align*} $$接著對輸入的 $\bs u_1$ 進行偏微分,並以 $\bs H_1$ 儲存結果
$$ \begin{align*} \frac{\partial E}{\partial \bs u_1} & = \frac{\partial E}{\partial \bs h} \frac{\partial \bs h}{\partial \bs u_1} = \bs W_2 \bs H_2 \circ \bs h \circ (\bs 1 - \bs h) = \bs H_1 \end{align*} $$最後再對權重 $\bs W_1$ 進行偏微分
$$ \begin{align*} \frac{\partial E}{\partial \bs W_1} & = \frac{\partial E}{\partial \bs u_1} \frac{\partial \bs u_1}{\partial \bs W_1} = \bs x \bs H_1^T = \bs G_1 \end{align*} $$已知 $\bs W_1$ 與 $\bs W_2$ 的梯度後,即可透過下列方式迭代
$$ \begin{align*} \bs W_1^{(\text{new})} & = \bs W_1^{(\text{old})} - \eta \bs G_1 \\ \bs W_2^{(\text{new})} & = \bs W_2^{(\text{old})} - \eta \bs G_2 \end{align*} $$上述的方式中,在對輸出偏微分時會出現 $\bs E_{i}$ 能在下一層的微分再次使用,以此計算出後一項的 $\bs E_{i - 1}$;其中的 $\bs W_2 \bs E_2$ 被視為是隱藏層 $h$ 的"預測誤差",若增加更多的隱藏層也是同理