Netflix 資料視覺化
引言
Kaggle 上有個與 Netflix 有關的題目,約9000筆的資料,其中重要變數包含
| 名稱 | 解釋 | 類型 | 範圍 |
|---|---|---|---|
| show_id | 每部片的唯一識別碼 | 唯一類別 | |
| type | 標示為電視節目或電影 | 唯一類別 | TV show, Movie |
| title | 片名 | 唯一類別 | |
| country | 發布國家 | 唯一類別 | United States, France, ... |
| release_year | 發布年分 | 數值 | 1925~2020 |
| duration | 影集長度 / 電影時常 | 數值 | |
| listed_in | 影片特徵 | 多重類別 | Documentaries, Crime TV Shows, ... |
受到施承翰學長的BGG 桌遊圖 啟發,我根據其碩士論文復刻出一份自己的版本,目標在於對高維度資料進行視覺化。
資料視覺化
高維度或非數值型資料難以理解,因此一個好的資料視覺化有助於解釋資料趨勢或建模的結果。相較於建模,預測數值型可以追求最小 MSE,或是預測類別型追求最大 Accuracy;而資料視覺化並沒有一個明確指標,因此不妨看看其他被視為成功的案例,從過去到現在 10 個最佳資料視覺化範例。下列舉出好的視覺化大概會有以下特徵
準確性
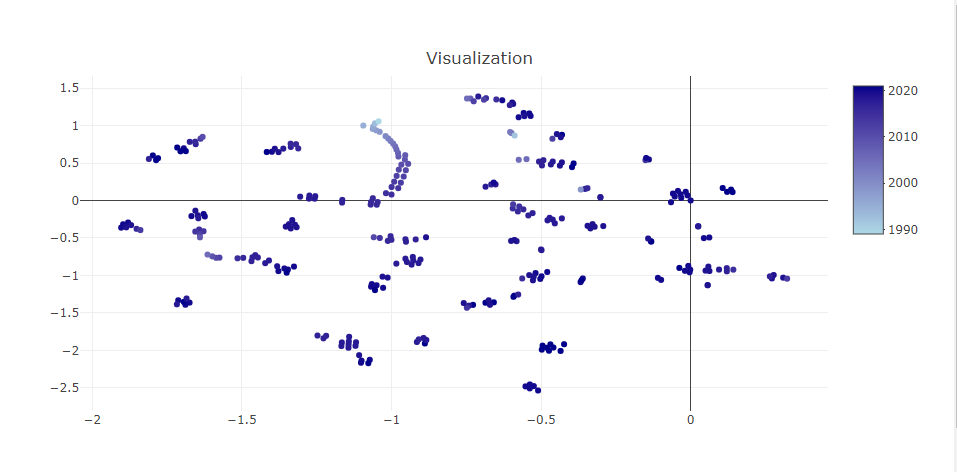
使用主成分分析 (PCA) 或 t-SNE 能將高維度投影到二維度,以至於能進行繪圖,雖然能看出整體的趨勢,但更高維度所含有的訊息卻可能被隱藏,而這也是降維繪圖最巨大的問題,因此在降維前要先針對資料與降維方法深究,否則可能會遺漏或錯用各種特徵。轉錄自承翰學長論文21頁
PC1 vs PC2 中兒童與恐怖遊戲混雜在一起,但 PC2 vs PC3 中就能明顯看出兒童與恐怖遊戲的距離。
這建構在我們擁有桌遊背景知識,若將主題切換至不熟悉的領域,這種錯誤的將「兒童遊戲」與「恐怖遊戲」認為是相近元素的認知可能會有致命的危險。
清晰性
文字大小、圖表類型、圖例或顏色都是該考慮的點。標籤雲(或稱文字雲)則是違反此特徵。
有效性
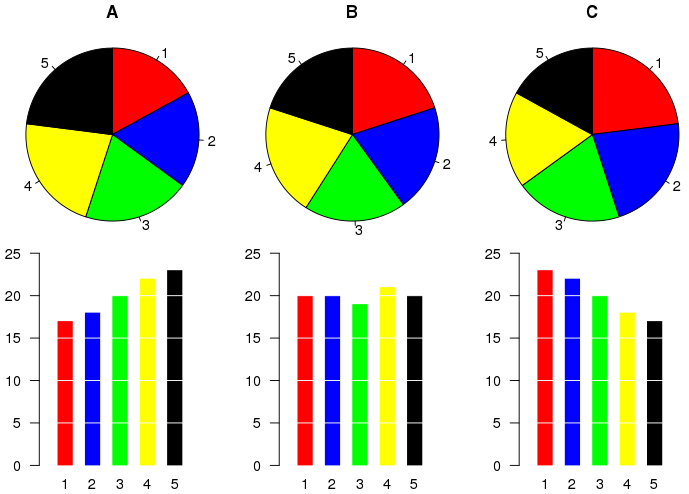
圖表應有效的傳遞出重要資訊。特別是人類對體積的感知不如長度,因此圓餅圖並不是一個好的選項。
互動性
降維的核心要點之一就是要將相近元素繪製在相鄰位置,但沒有給定目標前描述「相似」是有問題的描述,例如將一群人依相似度排序,可以根據身高、體重、年齡、性別等各種方式描述相似性,因此可以設計權重等方式讓用戶自行決定何種屬性為相近,例如承翰學長論文31頁,式子 (3.3)
$$ d_j = \sqrt{\frac{w_g * (d_g)^2+ w_c * (d_c)^2 + w_m * (d_m)^2}{w_g + w_c + w_m}} $$其中的 $w_g$、$w_c$ 與 $w_m$ 權重。
類別型變數
這筆資料有數個類別型變數,使用 one-hot encoding 處理產生的問題是稀疏 (Sparse,大部分資料紀錄都是 0),但仍能發現一些現象。例如
- 一部電影對應多種標籤(例如恐怖、浪漫),而一個標籤也對應多部電影,這就是「一物件對多類別,一類別對應多物件」。
- 一部電影對應只能在一個國家發布,而一個國家能發布多部電影,這就是「一物件對少類別,一類別對應多物件」。
| 物件 (object) | 類別 (class) | 範例 | 處理方式 |
|---|---|---|---|
| 一物件多類別 | 一類別多物件 | 電影類別 | jaccard similarity, PCA |
| 一物件多類別 | 一類別少物件 | 文字探勘 | LDA |
| 一物件少類別 | 一類別多物件 | 發布國家 | |
| 一物件少類別 | 一類別少物件 | 電影名稱 |
距離
描述兩個物件之間的距離,可以單純的用歐式距離
$$ \begin{align*} d (x, y) = \sqrt{ \sum_{j = 1}^{p} (x_j - y_j)^2 } \end{align*} $$$$ \begin{align*} d (x, y) = \sum_{j = 1}^{p} |x_j - y_j| \end{align*} $$如下範例
| Class 1 | Class 2 | Class 3 | |
|---|---|---|---|
| Object 1 | 1 | ||
| Object 2 | 1 | 1 | |
| Object 3 | 1 |
在歐式距離下,能看出 Object 2 與 Object 1 的距離和 Object 2 與 Object 3 的距離是相同的。
$$ \begin{align*} d (\text{Object 1, Object 2}) = d (\text{Object 1, Object 3}) = 1 \end{align*} $$但若為 class 放上名稱,例如
| 戰爭 | 二戰 | 浪漫 | |
|---|---|---|---|
| Object 1 | 1 | ||
| Object 2 | 1 | 1 | |
| Object 3 | 1 |
很明顯能得知二戰主題是戰爭主題的子集合,合理的假設 Object 1 與 Object 2 的距離應該小於 Object 1 與 Object 3,因此需找出 class 之間的關係。
Jaccard Similarity
描述兩集合 $A$, $B$ 相似度的方式,
$$ \begin{align*} J (A, B) = \frac{|A \cap B|}{|A \cup B|} \in [0, 1] \end{align*} $$如下範例
| Class 1 | Class 2 | Class 3 | |
|---|---|---|---|
| Object 1 | 1 | ||
| Object 2 | 1 | 1 | |
| Object 3 | 1 |
能描述出 Object 或 Class 之間的相似度,例如
$$ \begin{align*} J (\text{Object 1, Object 2}) = \frac{| \{ \text{Class 1} \} |}{| \{ \text{Class 1, Class 2} \} |} = \frac{1}{2} \end{align*} $$或者
$$ \begin{align*} J (\text{Class 1, Class 2}) = \frac{| \{ \text{Object 1} \} |}{| \{ \text{Object 1, Object 2} \} |} = \frac{1}{2} \end{align*} $$計算出 Class 相似度矩陣
| Class 1 | Class 2 | Class 3 | |
|---|---|---|---|
| Class 1 | 1 | 0.5 | 0 |
| Class 2 | 0.5 | 1 | 0 |
| Class 3 | 0 | 0 | 1 |
相似度矩陣的 PCA 結果為
| PC 1 | PC 2 | PC 3 | |
|---|---|---|---|
| Class 1 | 0.514 | 0.707 | 0.485 |
| Class 2 | 0.514 | -0.707 | 0.485 |
| Class 3 | -0.686 | 0.728 |
將原始資料的 class 轉換為 PC 結果
| PC 1 | PC 2 | PC 3 | |
|---|---|---|---|
| Object 1 | 0.228 | 0.707 | -0.243 |
| Object 2 | 0.743 | 0 | 0.243 |
| Object 3 | -0.972 | 0 | 0 |
此時就能得出 Object 1 與 Object 2 的距離小於 Object 1 與 Object 3 的結果
$$ \begin{align*} 1 = d (\text{Object 1, Object 2}) < d (\text{Object 1, Object 3}) = 1.414 \end{align*} $$Jaccard Similarity vs Correlation
Correlation 會將 0 視為是一種相似,而 Jaccard Similarity 不會。例如
| 戰爭 | 二戰 | 浪漫 | |
|---|---|---|---|
| Object 1 | 1 | 0 | 0 |
| Object 2 | 1 | 1 | 0 |
Object 1 與 Object 2 的 Similarity 和 Correlation 都是 0.5。若情況變成
| 戰爭 | 二戰 | 浪漫 | 競速 | |
|---|---|---|---|---|
| Object 1 | 1 | 0 | 0 | 0 |
| Object 2 | 1 | 1 | 0 | 0 |
Object 1 與 Object 2 的 Similarity 仍然是 0.5,但 Correlation 則是 0.58。
對於稀疏矩陣來說,用 Correlation 表述物件間的相似程度容易受到大量的 0 影響,導致相關係數上升;然而 Similarity 只考慮有 1 的地方,因此對於不斷新增無關的 class 都能保持一致性。