邏輯回歸羅吉斯迴歸分析 (Logistic Regression)
簡介
我們所熟悉的線性回歸並不適用於預測類別型變數,會有下列問題
- 不適合描述機率:線性回歸的範圍是 $\bb R$。
- 不適合描述非線性關係。
二元分類問題
假設 $Y_i \sim \ber (p_i)$, $p_i \in (0, 1)$,並用給定的 $(x_{i1}, x_{i2}, \cdots, x_{ik})_{i = 1}^{n}$ 預測 $p_i$。
邏輯函數 (Logistic Function or Sigmoid Function)
邏輯函數 $\sigma : \bb R \to (0, 1)$:
$$ \begin{align*} \sigma (x) = \frac{\exp (x)}{1 + \exp (x)} = \frac{1}{1 + \exp (-x)} \end{align*} $$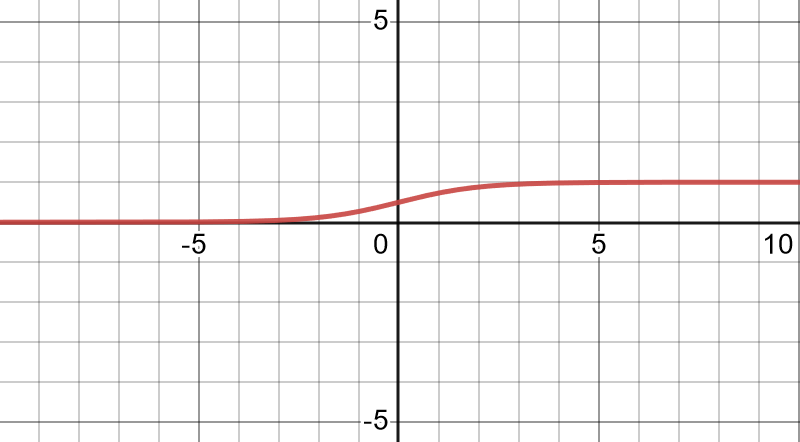
現考慮將原始資料 ($X$) 的線性組合
$$ \begin{align*} \bs X_i = \begin{pmatrix} 1 \newline X_{i1} \newline \vdots \newline X_{ik} \end{pmatrix}, \bs \beta = \begin{pmatrix} \beta_0 \newline \beta_1 \newline \vdots \newline \beta_k \end{pmatrix} \end{align*} $$並透過 $\sigma$ 轉換將值域從 $\bb R$ 轉換至 $(0, 1)$,並用此預測 $p_i$
$$ \begin{align*} \hat p_i = \sigma (\bs X_i^T \bs \beta) = \frac{\exp (\bs X_i^T \bs \beta)}{1 + \exp (\bs X_i^T \bs \beta)} \end{align*} $$損失函數 (Loss Function)
如同線性回歸的目標,我們需要找一個損失函數來評估預測的好壞
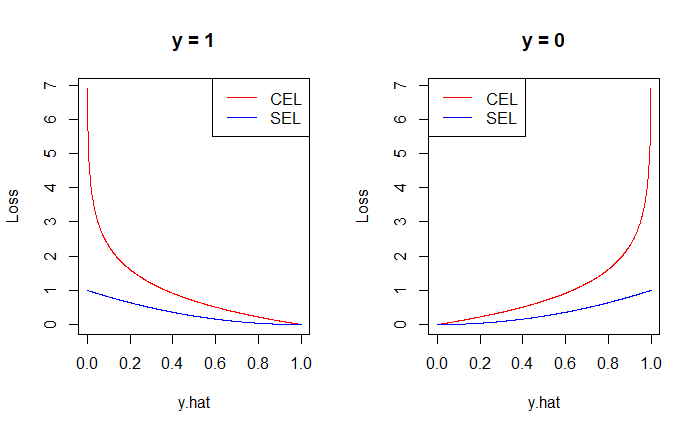
平方損失函數 (Square Error Loss, SEL)
我們不會使用在線性回歸裡的平方損失函數
$$ \begin{align*} SEL = (y - \hat p)^2 \end{align*} $$原因是真實的 $y$ 取值範圍僅有 $\{0, 1\}$,而預測的 $\hat p \in (0, 1)$,使得 $SEL$ 的範圍僅有 $(0, 1)$,這樣的損失函數太弱不適用於邏輯回歸。
Cross-Entropy Loss (CEL)
在邏輯回歸中我們會用 Cross-Entropy Loss,我就不強行翻譯成交叉熵,後續就簡稱 CEL。選擇 CEL 的原因參見 generalized linear model 的 natural link function。
$$ \begin{align*} CEL & = \begin{cases} -\ln ( \hat{p} ) & \text{ if } y = 1 \newline -\ln ( 1 - \hat{p} ) & \text{ if } y = 0 \newline \end{cases} \newline & = - y \ln (\hat p) - (1 - y) \ln (1 - \hat p) \end{align*} $$$CEL$ 的取值範圍在 $(0, \infty)$,更適用於評估邏輯回歸的好壞。
則 $n$ 筆資料的總損失量為
$$ \begin{align*} CEL & = \sum_{i = 1}^{n} - y_i \ln (\hat p_i) - (1 - y_i) \ln (1 - \hat p_i) \newline & = - \sum_{y_i = 1} \ln (\hat p_i) - \sum_{y_i = 0} \ln (1 - \hat p_i) \end{align*} $$而 $\beta$ 的目標是最小化損失量
$$ \begin{align*} \hat {\bs \beta} & = \argmin_{\bs \beta \in \bb R^p} \ CEL \newline & = \argmax_{\bs \beta \in \bb R^p} \ -CEL \newline & = \argmax_{\bs \beta \in \bb R^p} \ \sum_{y_i = 1} \ln (\hat p_i) + \sum_{y_i = 0} \ln (1 - \hat p_i) \end{align*} $$其中的 $\sum_{y_i = 1} \ln (\hat p_i) + \sum_{y_i = 0} \ln (1 - \hat p_i)$ 是 $\bs \beta$ 的 log-likelihood function,要讓其最小化等價於最小化 likelihood function
$$ \begin{align*} \hat {\bs \beta} & = \argmax_{\bs \beta \in \bb R^p} \ L (\bs \beta) \newline & = \argmax_{\bs \beta \in \bb R^p} \ \prod_{y_i = 1} \hat p_i \prod_{y_i = 0} (1 - \hat p_i) \newline & = \argmax_{\bs \beta \in \bb R^p} \ \prod_{i = 1}^{n} \hat p_i^{y_i} (1 - \hat p_i)^{1 - y_i} \end{align*} $$其中的 $\prod_{i = 1}^{n} \hat p_i^{y_i} (1 - \hat p_i)^{1 - y_i}$ 就是 $Y$ 的 joint density ($Y_i \sim \ber (p_i)$)。
參數估計
我們會用 maximum likelihood estimation (MLE) 來估計 $\bs \beta$,目標在解 log-likelihood 的最大值
$$ \begin{align*} l (\bs \beta) = \sum_{i = 1}^{n} Y_i (\bs X_i^T \bs \beta) - \ln \left( 1 + \exp (\bs X_i^T \bs \beta) \right) \end{align*} $$對其取一階偏導之後設為$0$
$$ \begin{align*} \begin{cases} \dps 0 = \frac{\partial l}{\partial \beta_0} = \sum_{i = 1}^{n} (y_i - \hat p_i) \newline \dps 0 = \frac{\partial l}{\partial \beta_j} = \sum_{i = 1}^{n} (y_i - \hat p_i) x_{ij} & j = \conti{k} \end{cases} \end{align*} $$但 $\bs \beta$ 並沒有準確值,一般是用數值方法的逼近解
$$ \begin{align*} \hat p_i = \sigma (\bs X_i^T \bs \beta) = \frac{\exp (\bs X_i^T \bs \beta)}{1 + \exp (\bs X_i^T \bs \beta)} \end{align*} $$將變數移項之後,得出擬合邏輯響應函數 (fitted logit response function),視為是資料的線性組合函數。
$$ \begin{align*} \tilde p_i = \ln \left( \frac{\hat p_i}{1 - \hat p_i} \right) = \bs X_i^T \bs \beta \end{align*} $$範例
用來自 wiki 的資料 資料
- 學習時間 (time, $x$):數值型變數,單位是小時。
- 是否通過 (pass, $y$):類別型變數,1為通過,0為未通過。
| Time | Pass |
|---|---|
| 0.50 | 0 |
| 0.75 | 0 |
| 1.00 | 0 |
| … | … |
| 5.00 | 1 |
| 5.50 | 1 |
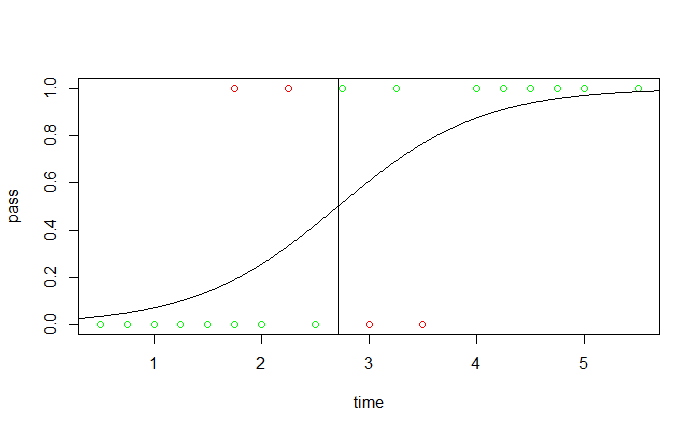
根據 MLE 解出 $\beta_0 = -4.1$ 和 $\beta_1 = 1.5$,代入
$$ \begin{align*} \hat y = f (x) = \frac{\exp (\beta_0 + \beta_1 x)}{1 + \exp (\beta_0 + \beta_1 x)} \end{align*} $$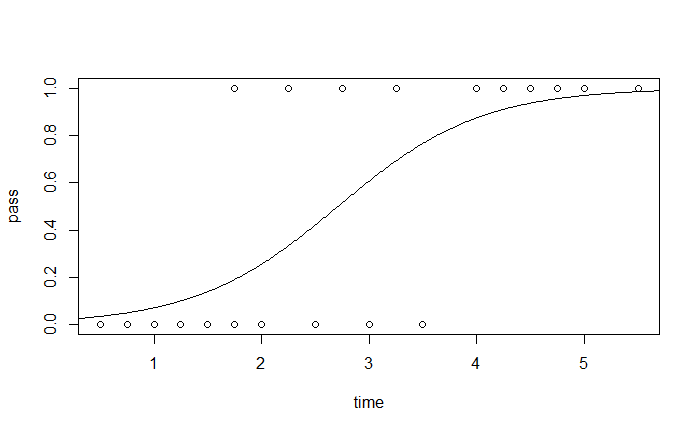
找出 $f (x) = 0.5$ 對應的 $x$,預測結果 $\hat y = I (f (x) \geq 0.5)$,綠色是正確預測,紅色則為錯誤預測。
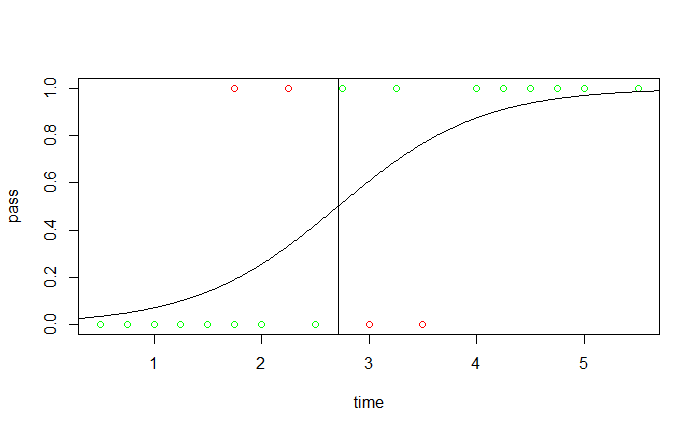
參數解釋
考慮簡單邏輯回歸
$$ \begin{align*} \hat p (x) = \frac{\exp (\beta_0 + \beta_1 x)}{1 + \exp (\beta_0 + \beta_1 x)} \end{align*} $$與對應的 fitted logit response function
$$ \begin{align*} \tilde p (x) = \ln \left( \frac{\hat p (x)}{1 - \hat p (x)} \right) = \beta_0 + \beta_1 x \end{align*} $$其中 $\hat p / (1 - \hat p)$ 稱為 勝算 (odd) 而 $\tilde p$ 稱為 勝算對數 (log odd),經過移項後
$$ \begin{align*} \beta_1 = \tilde p (x + 1) - \tilde p (x) = \ln \left( \frac{\hat p(x + 1)}{1 - \hat p(x + 1)} / \frac{\hat p (x)}{1 - \hat p (x)} \right) \end{align*} $$估計的 勝算比 (odds ratio) 為
$$ \begin{align*} \hat {OR} = \frac{\hat p(x + 1)}{1 - \hat p(x + 1)} / \frac{\hat p (x)}{1 - \hat p (x)} = \exp (\beta_1) \end{align*} $$在上一個例子中 $\beta_1 = 1.5$,這表示"每多增加一小時讀書時間,就會增加 $\exp (1.5) - 1 \approx 350\%$ 的通過考試的勝算"。
多元分類問題
若 $Y$ 現有 $J$ 種可能的取值範圍,即 $\text{Range} (Y) = \{ \conti J \}$ 對 $Y_i$ 做獨熱編碼 (one-hot encoding)
$$ \begin{align*} Y_{ij} & = \begin{cases} 1 & \text{if } Y_i = j \newline 0 & \text{if } Y_i \ne j \end{cases} \end{align*} $$假設 $Y_i \sim \text{Multinomial} (1; p_{i1}, p_{i2}, \cdots, p_{iJ})$ 且 $\sum_{j = 1}^{J} p_{ij} = 1$,即
$$ \begin{align*} P (Y_{ij} = 1) = p_{ij} \end{align*} $$基線分類邏輯 (Baseline Category Logits)
選定 $J$ 作為基線,將 $J$ 元分類問題轉換成 $J - 1$ 個 $2$ 元分類問題,每個問題考慮"是第 $j$ 還是第 $J$ 類"。令第 $j$ 與第 $J$ 類的 fitted logit response function 為
$$ \begin{align*} \tilde p_{ij} = \ln \left( \frac{p_{ij}}{p_{iJ}} \right) = \bs X_i^T \bs \beta_j \end{align*} $$若要比較第 $k$ 或第 $l$ 類,則可寫成
$$ \begin{align*} \ln \left( \frac{p_{ik}}{p_{il}} \right) & = \ln \left( \frac{p_{ik}}{p_{iJ}} \right) - \ln \left( \frac{p_{il}}{p_{iJ}} \right) \newline & = \bs X_i^T (\bs \beta_k - \bs \beta_l) \end{align*} $$將 $J$ 類的所有機率比較出來
$$ \begin{align*} p_{ij} = \begin{cases} \dps \frac{\exp (\bs X_i^T \bs \beta_j)}{1 + \sum_{k = 1}^{J - 1} (\bs X_i^T \bs \beta_k) } & j = \conti{J - 1} \newline \dps \frac{1}{1 + \sum_{k = 1}^{J - 1} (\bs X_i^T \bs \beta_k) } & j = J \newline \end{cases} \end{align*} $$這表示在給定 $X_i$ 下,認為是第 $j$ ($1 \leq j \leq J$) 類的機率是 $p_{ij}$,會選擇最高機率的類別作為最後的預測結果
$$ \begin{align*} \hat Y_i = \argmax_{j \in \\\{\conti{J}\\\}} p_{ij} \end{align*} $$參數估計
在多元分類問題也同樣是解 MLE,差別在 $\ut Y$ 的 joint density 為
$$ \begin{align*} f (\ut y) = \prod_{i = 1}^{n} f (y_i) = \prod_{i = 1}^{n} \prod_{j = 1}^{J} p_{ij}^{Y_{ij}} \end{align*} $$我們要最大化的 log-likelihood 目標變成
$$ \begin{align*} l (\contia{\bs \beta}{J - 1}) = \sum_{i = 1}^{n} \sum_{j = 1}^{J - 1} {\Bigr[ } Y_{ij} (\bs X_i^T \bs \beta_j) - \ln \left[ 1 + \exp (\bs X_i^T \bs \beta_j) \right] {\Bigr] } \end{align*} $$參數的推論屬性
漸進 MLE
若 $\bs b$ 是 $\bs \beta$ 的 MLE,則當 $n \to \infty$,我們有如下漸進常態分布
$$ \begin{align*} \bs b - \bs \beta \approx N (0, s^2 (\bs b)) \end{align*} $$其中 $s^2 (\bs b)$ 是漸進變異與共變異數矩陣,如下定義
$$ \begin{align*} s^2 (\bs b) = [- \triangledown^2 l (\bs b)]^{-1} \end{align*} $$其中 $- \triangledown^2 l (\bs b)$ 稱為 observed Fisher information。
推論
observed Fisher information 是一個 $k \times k$ 的矩陣,其中的第$lm$的元素是
下面是推論證明。首先 $\bs \beta$ 的 log-likelihood function 是
$$ \begin{align*} l (\bs \beta) & = \sum_{i = 1}^{n} Y_i (\bs X_i^T \bs \beta) - \ln \left( 1 + \exp (\bs X_i^T \bs \beta) \right) \newline & = \sum_{i = 1}^{n} Y_i \left( \sum_{j = 0}^{k} X_{ij} \beta_j \right) - \ln \left( 1 + \exp \left( \sum_{j = 0}^{k} X_{ij} \beta_j \right) \right) \end{align*} $$對其做一階偏導
$$ \begin{align*} \frac{\partial}{\partial \beta_l} l (\bs \beta) & = \sum_{i = 1}^{n} Y_i X_{il} - X_{il} \left( \frac{\exp \left( \sum_{j = 0}^{k} X_{ij} \beta_j \right)}{1 + \exp \left( \sum_{j = 0}^{k} X_{ij} \beta_j \right) } \right) \newline & = \sum_{i = 1}^{n} Y_i X_{il} - X_{il} \sigma \left( \sum_{j = 0}^{k} X_{ij} \beta_j \right) \end{align*} $$與二階偏導
$$ \begin{align*} \frac{\partial^2}{\partial \beta_l \partial \beta_m} l (\bs \beta) & = - \sum_{i = 1}^{n} X_{il} X_{im} \sigma' \left( \sum_{j = 0}^{k} X_{ij} \beta_j \right) \newline & = - \sum_{i = 1}^{n} X_{il} X_{im} \sigma' \left( \bs X_i^T \bs \beta \right) \end{align*} $$移項並帶入 $\bs \beta = \bs b$,獲得
$$ \begin{align*} - \left. \frac{\partial^2}{\partial \beta_l \partial \beta_m} l (\bs \beta) \right|_{\bs \beta = \bs b} & = \sum_{i = 1}^{n} X_{il} X_{im} \sigma' (\bs X_i^T \bs b) \end{align*} $$對任一個 $j = \contio{k}$,定義 $s (b_j) = [s (\bs b)]_{jj}$,皆有以下屬性
$$ \begin{align*} \frac{b_j - \beta_j}{s (b_j)} \xrightarrow{D} N (0, 1) \end{align*} $$單變數假設檢定 (Wald Test)
假設檢定
$$ \begin{align*} H : \beta_j = c \quad \text{against} \quad A : \beta_j \ne c \end{align*} $$漸進檢定統計量為
$$ \begin{align*} z^* = \frac{b_j - c}{s (b_j)} \end{align*} $$在顯著水準 $\alpha \in (0, 1)$ 下
- 若 $z^* \leq z_{\alpha / 2}$ 推論 $H$
- 若 $t^* > z_{\alpha / 2}$ 推論 $A$
信賴區間
對 $\beta_j$ 的 $1 - \alpha$ 漸進信賴區間為
$$ \begin{align*} b_j \pm s (b_j) z_{\alpha / 2} \end{align*} $$因此對勝算比 $\exp (\beta_j)$ 的漸進信賴區間為
$$ \begin{align*} \exp \left( b_j \pm s (b_j) z_{\alpha / 2} \right) \end{align*} $$Likelihood Ratio Test
假設檢定
$$ \begin{align*} & H : \beta_q = \beta_{q + 1} = \cdots = \beta_{p - 1} = 0 && (\text{簡化模型}) \newline & A : \text{exists } \beta_j = 0, \text{ for } j = q, q + 1, \cdots, p - 1 && (\text{完整模型}) \end{align*} $$漸進檢定統計量為
$$ \begin{align*} G^2 = -2 \ln \left( \frac{L_r}{L_f} \right) = -2 [l_r - l_f] \end{align*} $$其中 $L_r$ 和 $l_r$ 是簡化模型的 log-likelihood 與 log-likelihood,而 $L_f$ 和 $l_f$ 是簡化模型的 log-likelihood 與 log-likelihood。
在顯著水準 $\alpha \in (0, 1)$ 下
- 若 $G^2 \leq \chi_{p - q}^2 (1 - \alpha)$ 推論 $H$
- 若 $G^2 > \chi_{p - q}^2 (1 - \alpha)$ 推論 $A$
R 語言範例
library(nnet)
data = iris
model = multinom(Species ~ ., data = data)
summary(model)
# 混淆矩陣
predictions = predict(model, newdata = data)
confusion_matrix = table(data$Species, predictions)
print(confusion_matrix)
# 精確度
accuracy = sum(diag(confusion_matrix)) / sum(confusion_matrix)
print(paste("Accuracy:", accuracy))
結果:
Coefficients:
(Intercept) Sepal.Length Sepal.Width Petal.Length Petal.Width
versicolor 18.69037 -5.458424 -8.707401 14.24477 -3.097684
virginica -23.83628 -7.923634 -15.370769 23.65978 15.135301
Std. Errors:
(Intercept) Sepal.Length Sepal.Width Petal.Length Petal.Width
versicolor 34.97116 89.89215 157.0415 60.19170 45.48852
virginica 35.76649 89.91153 157.1196 60.46753 45.93406
Residual Deviance: 11.89973
AIC: 31.89973
predictions
setosa versicolor virginica
setosa 50 0 0
versicolor 0 49 1
virginica 0 1 49
[1] "Accuracy: 0.986666666666667"
參考資料
Applied linear statistical models. NETER, John, et al. 1996.