Latent Dirichlet Allocation (LDA) 應用
介紹
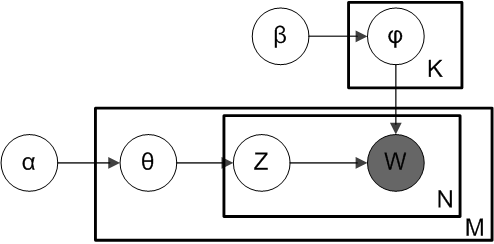
Latent dirichlet allocation (LDA) 一種常用於文字探勘的非監督式機器學習,目標是將大量文件 (documents),依據其使用單字 (words) 頻率,為其生成主題分佈 (topics),以此達成文件分類,也能應用於推薦系統,連結的文章會介紹 LDA 理論。
文本分類
分詞
LDA 的經典應用是文本分類,首先將一句話拆成各個單字,例如
吃葡萄不吐葡萄皮,不吃葡萄倒吐葡萄皮
吃、葡萄、不、吐、葡萄、皮、不、吃、葡萄、倒、吐、葡萄、皮
注意,英文可以直接以空格作為分詞依據,但中文則需分詞模型。
接著統計各字出現頻率
| 吃 | 葡萄 | 不 | 吐 | 皮 | 倒 |
|---|---|---|---|---|---|
| 2 | 4 | 2 | 2 | 2 | 1 |
將大量文章進行分詞後可獲得大致為以下的詞頻 (term-frequency) 矩陣
| 文章\單字 | 數學 | 函數 | 勝率 | 體育 | 運動 | … |
|---|---|---|---|---|---|---|
| 文章 1 | 3 | 4 | 1 | 0 | 0 | |
| 文章 2 | 0 | 0 | 1 | 3 | 2 | |
| … |
注意,文章會有大量不具有主題意義的詞,例如「有、不、好」等詞,稱為 stop words,一般在做文本分類會將 stop words 移除。
LDA 分佈
現在試想,我們實際僅觀測到文件與單字的關係,即「文件 <-> 單字」,體現為「詞頻 (term-frequency) 矩陣」。透過 LDA 模型生成機率模型,找出其中隱藏的主題層,即「文件 <-> 主題」與「 主題 <-> 單字」,分別體現為「單字矩陣」與「主題矩陣」的 2 個矩陣。
單字矩陣
| 主題\單字 | 數學 | 函數 | 勝率 | 體育 | 運動 | … |
|---|---|---|---|---|---|---|
| 主題 1 | 0.4 | 0.4 | 0.1 | 0.001 | 0.001 | |
| 主題 2 | 0.001 | 0.001 | 0.1 | 0.3 | 0.4 | |
| … |
觀察主題 1,其最高機率的單字為數學與函數,以此可能會命名為數學主題;觀察主題 2,其最高單字為體育與運動,以此可能會命名為體育學主題。
注意,LDA 能建構出主題,但主題數量仍得自選,在部分實證案例中,主題數量 20 是最佳數量。
主題矩陣
| 文章\主題 | 主題 1 | 主題 2 | 主題 3 | … |
|---|---|---|---|---|
| 文章 1 | 0.9 | 0.07 | 0.02 | |
| 文章 2 | 0.01 | 0.9 | 0.03 | |
| … |
觀察文章 1,其最高機率的主題為主題 1 (數學主題);文章 2 最高主題為主題 2 (體育);以此類推,因而做到主題分類。
降維比較
稀疏性
若將文本轉換至單字矩陣後,最明顯的特徵是稀疏性,即矩陣大多數空間為 0。以最經典的 主成分分析 (Principal Component Analysis, PCA) 比較,PCA 需計算到特徵向量,但過於稀疏的矩陣通常非滿秩 (non full rank),導致 PCA 的效益會非常糟,甚至在多數狀態下是無解。
另一種基於矩陣分解的奇異值分解 (Singular value decomposition, SVD) 衍伸的 Latent Semantic Analysis,雖解決了無解的問題,但無法解釋主題內單字的分佈,也無法解釋文件內主題的分佈。
過擬合
Latent Semantic Analysis (LSA) 的衍伸模型 Probabilistic Latent Semantic Analysis (pLSA) 加入了 Multinomial 的機率模型,使得能解釋主題內單字分佈與文件內主題的分佈,但卻這導致過度擬合 (over fitted) 的問題,在樣本數量不大的情況下泛化能力不高,即對樣本外的數據擴展效益不高。
機率模型
Latent Dirichlet Allocation 是 pLSA 的衍伸模型,引入 Dirichlet Distribution 作為先驗 (prior),對於新文件的泛化能力提升,決了過擬合的問題,但產生了隨機性問題,因最佳解不具有標準解 (closed form),一般會用採樣等近似法逼近最佳解,使得沒有固定隨機種子 (random seed) 下,任兩次的建模結果可能不同。(pLSA 可能用 EM 算法計算,在部分模型初始條件設定下,也可能具有隨機性)
應用
推薦系統
LDA 除了常用的文本分類外,也能應用於推薦系統,例如紀錄用戶購賣紀錄的矩陣
| 用戶\商品 | 商品 1 | 商品 2 | 商品 3 | 商品 4 | 商品 5 | … |
|---|---|---|---|---|---|---|
| 用戶 1 | 3 | 4 | 1 | 0 | 0 | |
| 用戶 2 | 0 | 0 | 1 | 3 | 2 | |
| … |
透過 LDA 能將「用戶 <-> 商品」擴展成「用戶 <-> 主題」與「主題 <-> 商品」兩個矩陣,將數種商品組合成一個主題,也能將用戶分群,群找與你相似的用戶用以推薦商品。
文本後續建模
評論網站上,可能可以蒐集到具有評論與評分的數據,若想找出評論與評分的關係,可以透過 LDA 先將評論從純文字轉換成 10 個主題分佈,再投入線性回歸等模型,以此建立文本與純字的關聯。
R 語言範例
選用以下範例 Spam Text Message Classification,此資料包含 5572 筆簡訊,並紀錄是否為垃圾郵件。首先安裝 package,主要功能為 tm 與 topicmodels 包,負責 text mining 與 LDA 模型。
library(dplyr) # %>%
library(tm) # text mining
library(SnowballC) # stem document
library(topicmodels) # LDA
安裝後讀取資料
data = read.csv("spam.csv", fileEncoding = "UTF-8")
執行預處理,一般分為 6 步驟
- 轉換文本為小寫
- 移除標點符號
- 移除數字
- 移除停用詞
- 移除空白
- 進行詞幹提取,例如將 running、ran 還原回 run
corpus = data$Message %>%
VectorSource() %>%
Corpus() %>%
tm_map(content_transformer(tolower)) %>% # 轉換為小寫
tm_map(removePunctuation) %>% # 移除標點符號
tm_map(removeNumbers) %>% # 移除數字
tm_map(removeWords, stopwords("en")) %>% # 移除英文停用詞
tm_map(stripWhitespace) %>% # 移除多餘的空白
tm_map(stemDocument) # 詞幹提取,來自 SnowballC
注意,此時可能會跳出 tm_map.SimpleCorpus() 中的警告:transformation drops documents,問題來自於預處理可能會導致空文本,例如僅有 “OK” 的簡訊在移除停用字後會變成空文本。此時先將問題簡化,暫且移除,並將資料轉換成詞頻矩陣。
dtm = DocumentTermMatrix(corpus)
dtm = dtm[which(rowSums(as.matrix(dtm)) != 0), ]
接著執行 LDA 模型,num_of_topic 為要分類的主題數量,此數字越大則運算時間越長。
num_of_topic = 2
lda = LDA(dtm, k = num_of_topic, control = list(seed = 0))
執行完後,觀察 LDA 的結果,並為各主題命名。
# 主題分佈
topic_distribution = posterior(lda)
# 最高主題分布
document_topics = topics(lda)
# token 分布
as.data.frame(terms(lda, 20))
中文分詞
中研院的詞庫小組 CKIP Lab 有提供繁體中文的分詞工具 CKIP CoreNLP。