Latent Dirichlet Allocation (LDA) 理論
介紹
Latent dirichlet allocation (LDA) 一種常用於文字探勘的非監督式機器學習,目標是將大量文件 (documents),依據其使用單字 (words) 頻率,為其生成主題分佈 (topics),以此達成文件分類,是 latent semantic analysis (LSA) 的擴展模型,連結的文章會介紹 LDA 應用。
LSA 假設
- 每個文件 (document) 是主題 (topics) 的 multinomial 分佈,稱為主題分佈
- 每個主題 (topics) 是單字 (words) 的 multinomial 分佈,稱為單字分佈
其中主題分佈與單字分佈都是未知的,僅有文件的用字頻率是已知的;而 LDA 引入 Dirichlet distribution,作為主題分佈與單字分佈的先驗 (prior) 分佈。
分配
Multinomial Distribution
假設有 $k$ 種可能的輸出,第 $i$ 種輸出的機率為 $p_i \geq 0$,且 $\sum_{i = 1}^{k} p_i = 1$,對應的出現次數為 $x_i$,則隨機變數 $\ut X = (\contia{X}{k})$ 有以下 PDF,
$$ \begin{align*} P (\ut X = \ut x | n, \ut p) & = \frac{n!}{\prod_{i = 1}^{k} (x_i)!} \prod_{i = 1}^{k} p_i^{x_i} \end{align*} $$其中 $\sum_{i = 1}^{k} x_i = n$,且 $x_i \in \bb N$ ($> 0$),寫作 $\ut X \sim \text{Mult} (n, \ut p)$;若 $n = 1$ 時,簡寫為 $\text{Mult} (\ut p)$。
Dirichlet Distribution
Dirichlet distribution 是 beta distribution 的擴展版,或稱 multivariate beta distribution。給定參數 $\ut \alpha = (\contia{\alpha}{k})$,$\alpha_i > 0$ 對任意 $i = \conti{k}$,則隨機變數 $\ut \theta = (\contia{\theta}{k})$ 有以下 PDF,
$$ \begin{align*} P (\ut \theta | \ut \alpha) & = \frac{\Gamma (\sum_{i = 1}^{k} \alpha_i)}{\prod_{i = 1}^{k} \Gamma (\alpha_i)} \prod_{i = 1}^{k} \theta_i^{\alpha_i - 1} \end{align*} $$其中 $\sum_{i = 1}^{k} \theta_i = 1$,且 $\theta_i \geq 0$ 對任意 $i = \conti{k}$,寫作 $\ut \theta \sim \text{Dir} (\ut \alpha)$。
Properties
$\Gamma (s)$ 是 gamma function,定義 multivariate beta function
$$ \begin{align*} B (\ut \alpha) & = \frac{\prod_{i = 1}^{k} \Gamma (\alpha_i)}{\Gamma (\sum_{i = 1}^{k} \alpha_i)} \end{align*} $$使得 Dirichlet distribution 的 PDF 寫成
$$ \begin{align*} P (\ut \theta | \ut \alpha) & = \frac{1}{B (\ut \alpha)} \prod_{i = 1}^{k} \theta_i^{\alpha_i - 1} \end{align*} $$因 PDF 的性質
$$ \begin{align*} 1 = \int P (\ut \theta | \ut \alpha) d \ut \theta = \frac{1}{B (\ut \alpha)} \int \prod_{i = 1}^{k} \theta_i^{\alpha_i - 1} d \ut \theta \end{align*} $$所以
$$ \begin{align*} B (\ut \alpha) = \int \prod_{i = 1}^{k} \theta_i^{\alpha_i - 1} d \ut \theta \end{align*} $$Conjugate Prior
$$ \begin{align*} \underbrace{p (\theta | x)}_{\text{posterior}} & = \underbrace{p (\theta)}_{\text{prior}} \times \underbrace{p (x | \theta)}_{\text{likehood}} \div \underbrace{p (x)}_{\text{marginal}} \\ & = \frac{p (\theta) p (x | \theta)}{\int p (\theta) p (x | \theta) d \theta} \\ & \propto p (\theta) p (x | \theta) \end{align*} $$若 prior $p (\theta)$ 和 posterior $p (\theta | x)$ 是相同類型的分佈,則稱此 prior 為 conjugate prior,而選用 conjugate distribution 能較容易從 prior 計算 posterior。
給定 $\ut X \sim \text{Mult} (n, \ut \theta)$,其中參數的 prior 為 $\ut \theta \sim \text{Dir} (\ut \alpha)$,則 posterior 為
$$ \begin{align*} p (\ut \theta | \ut x, \ut \alpha) & \propto p (\ut \theta | \ut \alpha) p (\ut x | \ut \theta) \\ & = \left[ \frac{1}{B (\ut \alpha)} \prod_{i = 1}^{k} \theta_i^{\alpha_i - 1} \right] \left[ \frac{n!}{\prod_{i = 1}^{k} (x_i!)} \prod_{i = 1}^{k} \theta_i^{x_i} \right] \\ & \propto \prod_{i = 1}^{k} \theta_i^{\alpha_i + x_i - 1} \end{align*} $$即 $\theta | \ut x, \ut \alpha \sim \text{Dir} (\ut x + \ut \alpha)$,因此 Dirichlet 為 Multinomial 的 conjugate prior。
模型定義
簡化模型
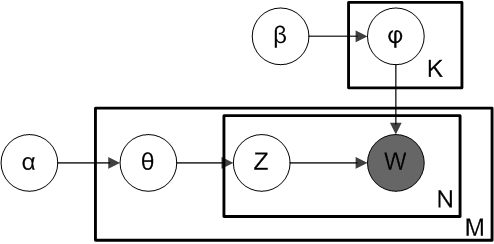
給定 $K$ 個主題、$V$ 種單字、參數 $\ut \alpha \in \bb R^{K}$ 和 $\ut \beta \in \bb R^{V}$,LDA 假設一份 $N$ 字的文件生成為順序為
- 生成每個主題下的單字分佈 $\ut {\varphi_k} \sim \text{Dir} (\ut \beta)$ 對 $k = \conti{K}$。
- 生成文件下的主題分佈 $\ut {\theta} \sim \text{Dir} (\ut \alpha)$。
- 生成文件下的單字
- 選定每個位置下的主題 $z_n \sim \text{Mult} (\ut \theta)$,對 $n = \conti{N}$。
- 選定每個位置下的單字 $w_n \sim \text{Mult} (\ut {\varphi_{z_n}})$,對 $n = \conti{N}$。
範例
例如2個主題、$100$個單字、參數 $\alpha = (2, 1)$ 表示為 (數學、體育) 和 $\beta = (2, 2, 0.1, 2, 2, \cdots)$ 表示為 (數字、函數、共軛、勝率、運動),則一份10個字的文件生成順序如下
- 生成每個主題下的單字分佈
- 例如主題1 $\ut {\varphi_1} = (0.4, 0.4, 0.08, 0.01, 0.01, \cdots)$,常用字為數字、函數、共軛
- 例如主題2 $\ut {\varphi_2} = (0.08, 0.01, 0.01, 0.4, 0.4, \cdots)$,常用字為勝率、運動
- 生成文件下的主題分佈
- 例如偏向數學主題 $\ut \theta = (0.9, 0.1)$
- 生成文件下的單字
- 因 $\phi$ 偏第1維度,$\text{Mult} (\ut \theta)$ 採樣結果容易為1,而不容易為2;假設 $z_1 = z_2 = \cdots = z_9 = 1$,$z_{10} = 2$。
- 生成第1個字,$w_1 \sim \text{Mult} (\ut {\varphi_{z_1}}) = \text{Mult} (\ut {\varphi_1})$ 容易出現數字、函數、共軛等字
- 生成第2個字,$w_2 \sim \text{Mult} (\ut {\varphi_{z_2}}) = \text{Mult} (\ut {\varphi_1})$ 容易出現數字、函數、共軛等字
- $\vdots$
- 生成第10個字,$w_{10} \sim \text{Mult} (\ut {\varphi_{z_{10}}}) = \text{Mult} (\ut {\varphi_2})$ 容易出現勝率、運動
在此範例中能看出,$\ut{\varphi_1}$ 與 $\ut{\varphi_2}$ 決定每個主題下的常用字。
完整模型
LDA 假設 $K$ 是已知的,實務上透過實驗選擇出來,某些實驗結果表明 20 種主題已經足夠;$\ut \alpha$ 與 $\ut \beta$ 若無先驗知識的情況下,建議將 $\ut \alpha$ 與 $\ut \beta$ 的所有分量均設為1。現在考慮 $K$ 個主題、$V$ 種單字、$M$ 份文件,文件字數分別為 $(\contia{N}{M})$ 則 LDA 的生成順序為
- 生成每個主題下的單字分佈 $\ut {\varphi_k} \sim \text{Dir} (\ut \beta)$ 對 $k = \conti{K}$。
- 生成每份文件下的主題分佈 $\ut {\theta_m} \sim \text{Dir} (\ut \alpha)$ 對 $m = \conti{M}$。
- 生成文件下的單字
- 選定每個位置下的主題 $z_{mn} \sim \text{Mult} (\ut {\theta_m})$,對 $m = \conti{M}$ 與 $n = \contia{N}{m}$
- 選定每個位置下的單字 $w_{mn} \sim \text{Mult} (\ut {\varphi_{z_{mn}}})$,對 $m = \conti{M}$ 與 $n = \contia{N}{m}$
其中 $\ut {\varphi_k}$ 決定每個主題下的單字分佈,$\ut {\theta_m}$ 決定每個文件的主題分佈。現在簡化符號
- 以 $\bs \varphi = \{\ut {\varphi_k}\}_{k = 1}^{K} \in \bb R^{K \times V}$ 表示單字分佈矩陣
- 以 $\bs \theta = \{\ut {\theta_m}\}_{m = 1}^{M} \in \bb R^{M \times K}$ 表示主題分佈矩陣
- 以 $\bs z = \{\ut {z_m}\}_{m = 1}^{M}$ 表示主題矩陣
- 以 $\bs w = \{\ut {w_m}\}_{m = 1}^{M}$ 表示單字矩陣
則給定參數 $\alpha$ 與 $\beta$ 後,完整的機率模型可以被表示為 $m$ 份文件的機率相乘
$$ \begin{align*} p (\bs w, \bs z, \bs \theta, \bs \varphi | \ut \alpha, \ut \beta) & = \prod_{k = 1}^{K} p (\ut {\varphi_k} | \ut \beta) \prod_{m = 1}^{M} p (\ut {\theta_m} | \ut \alpha) \prod_{n = 1}^{N_m} p (z_{mn} | \ut {\theta_m}) p (w_{mn} | \ut {\varphi_{z_{mn}}}) \\ & = \prod_{m = 1}^{M} p (\ut {w_m}, \ut {z_m}, \ut {\theta_m}, \bs \varphi | \ut \alpha, \ut \beta) \end{align*} $$其中第 $m$ 份文件的機率為
$$ \begin{align*} p (\ut {w_m}, \ut {z_m}, \ut {\theta_m}, \bs \varphi | \ut \alpha, \ut \beta) & = \prod_{k = 1}^{K} p (\ut {\varphi_k} | \ut \beta) p(\ut {\theta_m} | \ut \alpha) \prod_{n = 1}^{N_m} p (z_{mn} | \ut {\theta_m}) p (w_{mn} | \ut {\varphi_{z_{mn}}}) \end{align*} $$前半部的 $p (\ut {\varphi_k} | \ut \beta) p(\ut {\theta_m} | \ut \alpha)$ 為兩個獨立的 Dirichlet 機率,後半部的 $p (z_{mn} | \ut {\theta_m}) p (w_{mn} | \ut {\varphi_{z_{mn}}})$ 為兩步驟的 Multinomial 機率,然而 $\bs z$ 是未知的,僅有觀測到 $\bs w$,因此轉而計算 $(\ut {w_m} | \ut {\theta_m}, \bs \varphi)$ 的 marginal PDF
$$ \begin{align*} p (\ut {w_m} | \ut {\theta_m}, \bs \varphi) & = \sum_{k = 1}^{K} \left[ \prod_{n = 1}^{N_m} p (z_{mn} | \ut {\theta_m}) p (w_{mn} | \ut {\varphi_{z_{mn}}}) \middle| z_{mn} = k \right] \\ & = \prod_{n = 1}^{N_m} \left[ \sum_{k = 1}^{K} p (z_{mn} = k| \ut {\theta_m}) p (w_{mn} | \ut {\varphi_k}) \right] \end{align*} $$然而 $\bs \theta$ 與 $\bs \varphi$ 也仍然是未知的。再次計算條件機率,即可計算出給定 prior 參數 $\ut \alpha$ 與 $\ut \beta$ 下,每份文件出現的機率
$$ \begin{align*} p (\ut {w_m} | \ut \alpha, \ut \beta) & = \prod_{k = 1}^{K} \int \int p (\ut {\varphi_k} | \ut \beta) p (\ut {\theta_m} | \ut \alpha) p (\ut {w_m} | \ut {\theta_m}, \bs \varphi) d \ut {\theta_m} d \ut {\varphi_k} \end{align*} $$所有文件的 joint PDF 為
$$ \begin{align*} p (\bs w | \ut \alpha, \ut \beta) = \prod_{m = 1}^{M} p (\ut {w_m} | \ut \alpha, \ut \beta) \end{align*} $$參數估計
機率模型中包含3個隱藏參數 $\bs z$ (每個單字的主題)、$\bs \theta$ (主題分佈) 與 $\bs \varphi$ (單字分佈) 是估計目標,從 $\bs z$ 開始。考慮第1份文件,以 $w, z, \varphi, \theta$ 表示 第一份文件對應的 $\ut {w_1}, \ut {z_1}, \ut {\varphi_1}, \ut {\theta_1}$ ,在給定文件與參數下,每個單字的主題分佈機率如下
$$ \begin{align*} p (z | w, \ut \alpha, \ut \beta) = \frac{p (w, z | \ut \alpha, \ut \beta)}{p (w | \ut \alpha, \ut \beta)} \end{align*} $$分母的部分已知,而分子可以拆分為兩部分
$$ \begin{align*} p (w, z | \ut \alpha, \ut \beta) & = p (w | z, \ut \alpha, \ut \beta) p (z | \ut \alpha, \ut \beta) \\ & = p (w | z, \ut \beta) p (z |\ut \alpha) \end{align*} $$先處理第一部分,令 $\varphi_{kv}$ 為第 $k$ 個主題下,第 $v$ 個單字的機率,令$n_{kv}$ 為第 $k$ 個主題下,第 $v$ 個字出現的次數,且 $n_k = \{ n_{k1}, n_{k2}, \cdots, n_{kV} \}$
$$ \begin{align*} p (w | z, \ut \beta) & = \int p (w | z, \varphi) p (\varphi, \ut \beta) d \varphi \\ & = \int \left[ \prod_{k = 1}^{K} \prod_{v = 1}^{V} \varphi_{kv}^{n_{kv}} \right] \left[ \frac{1}{B (\ut \beta)} \prod_{v = 1}^{V} \varphi_{k_v}^{\beta_v - 1} \right] d \varphi \\ & = \prod_{k = 1}^{K} \frac{1}{B (\ut \beta)} \int \prod_{v = 1}^{V} \varphi_{kv}^{n_{kv} + \beta_v - 1} d \varphi \\ & = \prod_{k = 1}^{K} \frac{B (\ut {n_k} + \ut \beta)}{B (\ut \beta)} \end{align*} $$相似的,令 $n_{mk}$ 為第 $m$ 篇文件下,第 $k$ 個主題出現的次數,且 $n_m = \{ n_{m1}, n_{m2}, \cdots, n_{mK} \}$
$$ \begin{align*} p (z | \ut \alpha) & = \int p (z | \theta) p (\theta, \ut \alpha) d \theta \\ & = \prod_{m = 1}^{M} \frac{B (\ut {n_m} + \ut \alpha)}{B (\ut \alpha)} \end{align*} $$綜合上式,可獲得
$$ \begin{align*} p (w, z | \ut \alpha, \ut \beta) = \prod_{k = 1}^{K} \frac{B (\ut {n_k} + \ut \beta)}{B (\ut \beta)} \prod_{m = 1}^{M} \frac{B (\ut {n_m} + \ut \alpha)}{B (\ut \alpha)} \end{align*} $$使得
$$ \begin{align*} p (z | w, \ut \alpha, \ut \beta) = \frac{1}{p (w | \ut \alpha, \ut \beta)} \prod_{k = 1}^{K} \frac{B (\ut {n_k} + \ut \beta)}{B (\ut \beta)} \prod_{m = 1}^{M} \frac{B (\ut {n_m} + \ut \alpha)}{B (\ut \alpha)} \end{align*} $$不過其中的 $\ut {n_k}$ 與 $\ut {n_m}$ 是未知的,可以透過 Gibbs sampling 與下列式估計
$$ \begin{align*} P (z_i = k | \bs z_{-i}, w, \alpha, \beta) \propto \frac{n_{kv} + \beta_v}{\sum_{v = 1}^{V} (n_{kv} + \beta_v)} \cdot \frac{n_{mk} + \alpha_k}{\sum_{k = 1}^{K} (n_{mk} + \alpha_k)} \end{align*} $$參考資料
- LI, Hang. Machine Learning Methods. Springer Nature, 2023.
勘誤
這篇文章帶有一定量的錯誤,我會列出有錯誤的式子,紅色是錯誤,綠色是修正
$$ \begin{align} \tag{20.2} p (\theta | \alpha) = \frac{\Gamma \left( \sum_{i = 1}^{k} \alpha_i \right)}{\prod_{i = 1}^{k} \Gamma (\alpha)^{\color{red}{k}}} \prod_{i = 1}^{k} \theta_i^{\alpha_i - 1} \\ \notag p (\theta | \alpha) = \frac{\Gamma \left( \sum_{i = 1}^{k} \alpha_i \right)}{\prod_{i = 1}^{k} \Gamma (\alpha)} \prod_{i = 1}^{k} \theta_i^{\alpha_i - 1} \end{align} $$$$ \begin{align} \tag{20.16} & p (\bs w_m, \bs z_m, \theta_m, \varphi | \alpha, \beta) \\ \notag = & \prod_{k = 1}^{K} p (\phi_k | \beta) p (\theta_m | \alpha) \prod_{\textcolor{red}{m} = 1}^{N_m} p (z_{mn} | \theta_m) p (w_{mn} | z_{mn}, \varphi) \\ \notag = & \prod_{k = 1}^{K} p (\phi_k | \beta) p (\theta_m | \alpha) \prod_{\textcolor{green}{n} = 1}^{N_m} p (z_{mn} | \theta_m) p (w_{mn} | z_{mn}, \varphi) \end{align} $$$$ \begin{align} \tag{20.18} p (\bs w_m, | \theta_m, \varphi) & = \prod_{\textcolor{red}{n} = 1}^{K} \int p (\varphi_k | \beta) \\ \notag & = \prod_{\textcolor{green}{k} = 1}^{K} \int p (\varphi_k | \beta) \end{align} $$$$ \begin{align} \tag{20.23} p (w | z, \beta) & = \int p (w | z, \textcolor{red}{\beta}) p (\varphi | \beta) d \varphi \\ \notag & = \int p (w | z, \textcolor{green}{\varphi}) p (\varphi | \beta) d \varphi \\ \end{align} $$$$ \begin{align} \tag{20.27} & p (z_i | \text{z}_{-i}, w, \alpha, \beta) \\ \notag \propto & \frac{n_{kv} + \beta_v}{\sum_{v \textcolor{red}{-} 1}^{V} (n_{kv} + \beta_v)} \cdot \frac{n_{mk} + \alpha_k}{\sum_{k = 1}^{K} (n_{mk} + \alpha_k)} \\ \notag \propto & \frac{n_{kv} + \beta_v}{\sum_{v \textcolor{green}{=} 1}^{V} (n_{kv} + \beta_v)} \cdot \frac{n_{mk} + \alpha_k}{\sum_{k = 1}^{K} (n_{mk} + \alpha_k)} \\ \end{align} $$