
野生企業徵才觀察紀錄
封面是用 Stable Diffusion 繪製的「野生企業徵才觀察紀錄」。
原本是想像在非洲大草原上看到野生的企業(?)在河邊喝水

撰寫當下是碩士一年級的寒假,希望能趁現在多看一點、多想一點,為未來規劃好道路。這次的主要目標便是知道市場需求,趁有空補齊自身能力。
資料科學的工作
目前考慮的工作是
- 資料科學家
- 資料分析師
- 資料工程師
雖然部份工作內容的確是重疊的,但根據我在求職網站上的觀察,台灣的公司並沒有特別做區別,但我自己是期待都能作到,畢竟學習新技能也頗有趣的。
| 定義問題 | 數據蒐集 | 清理數據 | 探索性數據分析 | 建立模型 | 解釋結果 | |
|---|---|---|---|---|---|---|
| 工程師 | v | v | ||||
| 分析師 | ? | v | v | v | ||
| 科學家 | ? | v | v | v |
定義問題
就我理解,多數的案子問題都已經定義明確。然而也會有全開放性問題,就給了眾多資料,期待你能在資料中挖出有價值,因此這很考驗資料科學家如何預測公司期待的結果,並試著在資料中找出期中可能出現的結果。
數據蒐集
數據來源可能是問卷、爬蟲或資料庫。數據工程師所負責的是製作爬蟲、API與資料庫建立和維護。
清理數據
數據清理的乾淨程度嚴重影響到後續建模的難度,目前見過最髒的資料是來自 Google Map API 的資料,實際需要的內容只有經緯度與名稱,但取得的資料數量卻大的誇張;有些來自爬蟲的資料也是很髒,不經過一定程度的清洗基本無法使用,因此這需要一定程度的程式來自動化清理。
探索性資料分析 (Exploratory Data Analysis, EDA)
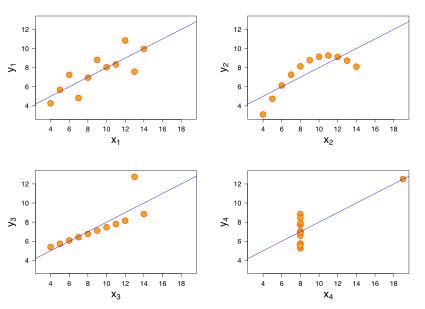
這個步驟所需要的是用統計方法對資料進行探索,例如利用可視化或簡單的模型來發覺資料特徵,參見 Anscombe’s quartet,下列4筆資料的 $X$ 平均、$X$ 變異數、$Y$ 平均、$Y$ 變異數、$X$ 與 $Y$ 的相關係數、回歸線、決定係數 $R^2$ 全都相同 (至少到小數點下2至3位相同),但卻擁有完全不一樣的特徵,因此這是希望能在此階段就發現的問題。
建立模型
長話短多說,根據資料特徵選擇機器學習、統計分析等方式,對選定的目標建立預測模型。
解釋結果
最後一步就是根據模型,有理有據的講出一個好故事,此時將結果可視化是一個很重要的考量,與其講的滿口 P-value 顯著性、$R^2$ 的解釋力, 不如一張圖表直接了當,還省得解釋背後各式統計數據所表示的定義。
我認為這也是在社會上存活的一項重要技能「如何長話短說」,大家都知道你統計能力很好,但如何把複雜的東西講的簡單易懂,才是一項對技術能力的真實理解。其中一個是例子是「你不用跟客戶解釋汽車內燃機的原理或引擎功率,你只需要提供對方所在忽的事情就好,例如這車在市長市場上來說引擎功率很好,而且售價也很合理,這樣就夠了。」
需求能力
在2024年2月所觀察的數據,我想分2部份描述現今市場所需的人才,一部份是硬實力或者說技術力,另一部份則是軟實力或者說合作能力,畢竟這年代凡是講求合作,一個人的能力畢竟有限,我們也是站在前人的肩膀上才有現在的社會。
硬實體
- 資料庫 SQL:現在公司擁有自己的資料庫似乎成為常態,以資料科學家為目標的話,資料庫可能不是主力項目,但有一點基本的資料庫操作能力可能還是必要的。
- 統計學:資料科學的基石,一個具有解釋力的模型其背後就是基於統計學理論做建構出來的,而我個人想做的是結構性問題,指的是單筆資料具有意義,例如「身高、體重、年紀」等性質的資料;相對應的非結構性問題,例如圖形辨識,單個像素點其實沒有任何解釋效力。對比的例子是「結構性問題能做到體重導致致死率的推論,但非結構性問題卻無法做到某個像素點導致推論出猴子圖片的推論。」
- 資料科學:建模與視覺化,包含各式回歸、隨機森林等模型和 PCA 與 t-SNE 等視覺化方法,也就是我們吃飯的工具。
- 程式能力 Python、R、SAS:講得一口好理論卻沒辦法實踐顯然是不行的,而各間公司使用的程式卻又都不太相同,這邊僅建議專精一項程式語言就夠了,學程式的時候重點在邏輯而非語法,若精通一項語言後再學其他程式語言會輕鬆很多。
- 大數據工具 Apache Hadoop、Apache Spark:對於巨大資料量與龐大計算量所誕生的分散式計算平台,不僅限 Apache 的產品,Google 和 Microsoft 也有類似的雲端運算平台,要能熟悉不同的作業系統與工作平台可能是必要的。
- 版本控制 Git:一個大型專案可能同時會有多組人同時分工,因此會需要有版本控制的需求,最常見的控制工具就是 Github
- 英文:老傳統,大家都在說。
軟實力
- 講故事能力:說明結果、提出建議、後續績效評估,理工學院的課程基本不會訓練到的技能,但卻是決定成敗的關鍵因素,畢竟模型做再好,對方聽不懂也全是白搭。
- 資料及數據分析經驗:這能被提早累積的,有不少大型企業,例如 Google 會在 Kaggle 上刊登題目,或許我們沒能力解如此高難度的題目,但也有如 playground 的友善題目能給我們提供寶貴的分析經驗。
- 有能力學數學以外的專業知識:畢竟資料科學算是一種應用數學,而客戶可能是來自金融、生醫或其他專業,雖然沒有背景知識還是能做資料分析,但若有背景知識則能知道對方領域所在乎的數據指標或資料間可能已經存在的關係,比較能做出對方想看且有價值的分析。
- 自主問題解決能力、橋接技術、高效執行能力、團隊合作的精神:老傳統。
成果累積
最後想提出一點,本人就是靠作品集才順利擠上碩士名額的,所以我非常推崇累積作品。而作品呈現也是建議多下功夫,不然大家都拿著差不多的文憑,沒有出色的經驗或作品真的沒人會記住你。
以下可以能提早準備的內容
- 自薦信
- 自傳
也有看到有公司可以準備大學專題、碩士論文、已發表的期刊或會議論文,主題不拘,面試當日紙本或簡報均可。
對於提供不一樣的選項,我建議