Continuous Bag of Word (CBOW) 與 Skip-Gram
引言
自然語言處理 (Natural Language Processing, NLP) 中得處理文本型資料,其中最經典的方式就是詞袋 (Bag of Word, BOW) 方式,其方式是統計文本中個單字的出現量,但難以顯示出近意字的概念,例如難以定義「輕鬆」與「簡單」兩個單字的相似度
文本向量化 (Word to Vector) 應運而生,收集大量文本的前後文關係,並用數學模型將文字轉換成高維度向量,若兩單字相近,則其轉換後的向量也會相近;連續詞袋 (Continuous Bag of Word, CBOW) 與 Skip-Gram 就是其中兩種經典方案。建議先了解類神經網路的架構再閱讀本文
Continuous Bag of Word (CBOW)
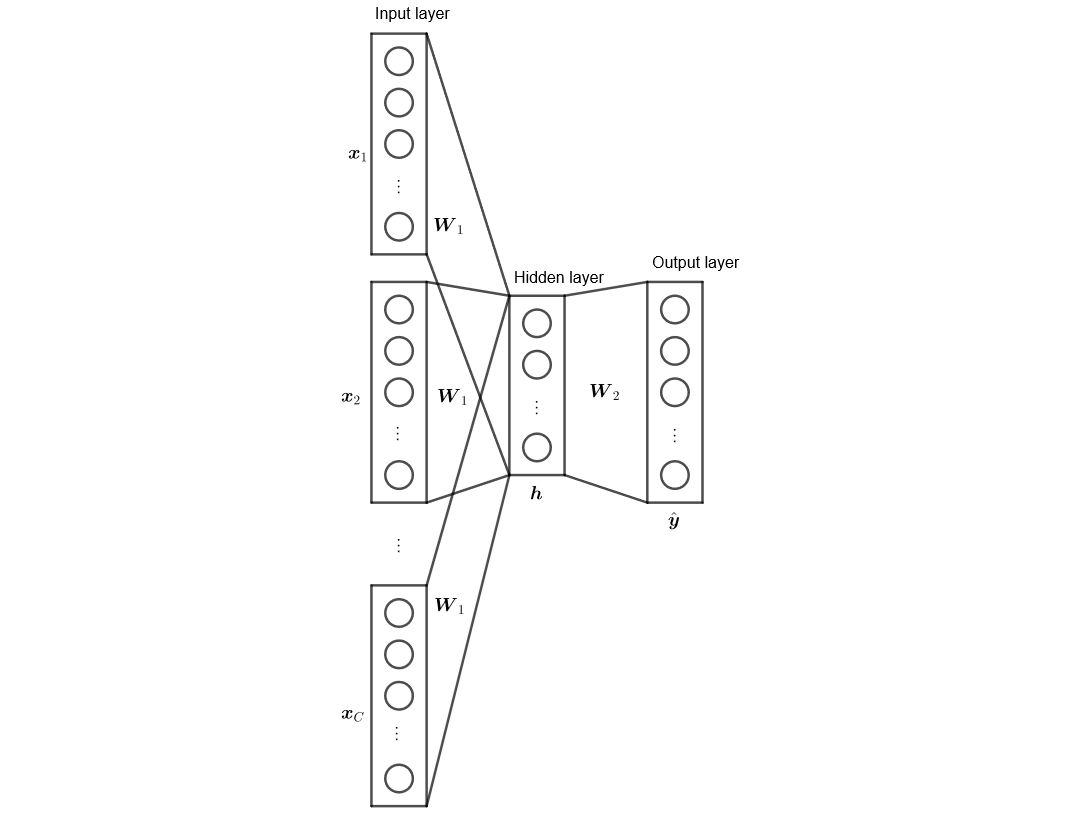
單輸入
考慮最簡單的情況,現給定一個字後,預測下一個字。設定單字量 $V$,單字 $\{ \contia{w}{V} \}$,$\bs x$ 是單字的 one-hot encoding,即第 $i$ 個單字的 $x_i = 1$,其餘 $x_j = 0$ 對 $j \ne i$;給定隱藏層大小 $N$,兩層權重 $\bs W_1 \in \bb R^{V \times N}$ 與 $\bs W_2 \in \bb R^{N \times V}$,$\hat y$ 是預測各單字機率
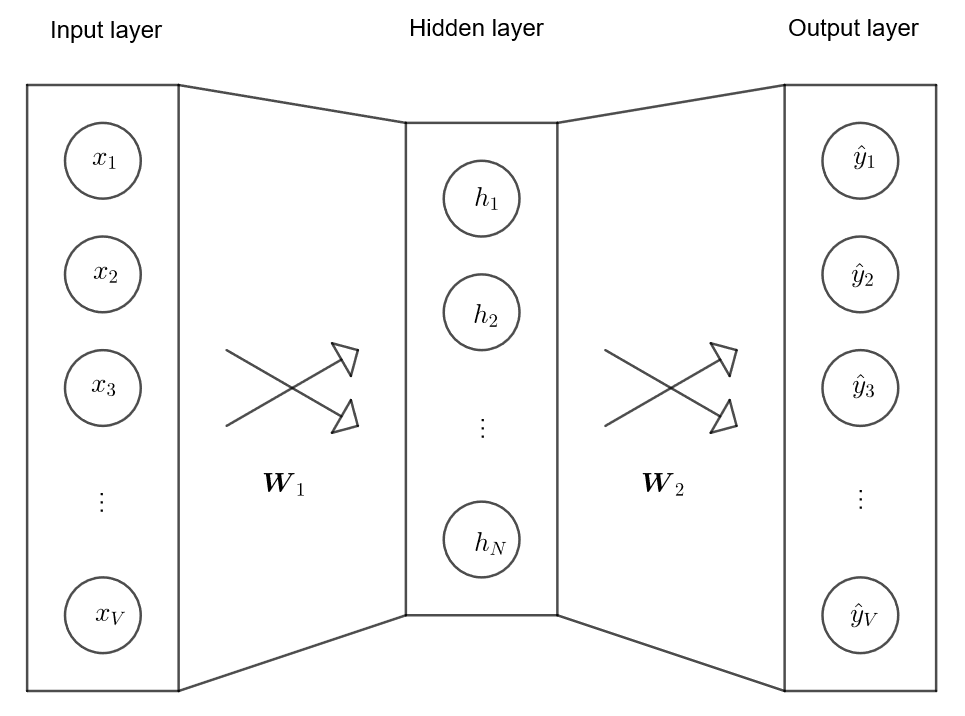
其操作如下,給定單字 $w$,與其對應的向量 $\bs x$,預測各單字的機率為
$$ \begin{align*} \bs h & = \bs W_1^T \bs x \\ \bs u & = \bs W_2^T \bs h \\ \hat {\bs y} & = \text{softmax} (\bs u) \end{align*} $$其中 $\text{softmax} (\bs u)$ 定義為
$$ \begin{align*} \hat y_j = \frac{\exp (u_j)}{\sum_{v = 1}^{V} \exp (u_v)} \end{align*} $$由於 $\bs x$ 是 one-hot encoding,使得
$$ \begin{align*} \bs h = \bs W_1^T \bs x_{w_i} = [\bs W_1^T]_{(i, \cdot)} = \bs v_{1, i}^T \end{align*} $$其中 $\bs v_{1, i}$ 是 $\bs W_1$ 的第 $i$ 列 (row),又稱輸入向量 (input vector)。另一方面,第 $j$ 個輸出單字的值為
$$ \begin{align*} u_j = [\bs W_2^T]_{(\cdot, j)} \bs h = \bs v_{2, j}^T \bs h \end{align*} $$其中 $\bs v_{2, j}$ 是 $\bs W_2$ 的第 $j$ 行 (column),又稱輸出向量 (output vector)。因此給定單字 $w_i$ 後,預測下一個單字的機率寫為
$$ \begin{align*} \hat y_j = p (w_j | w_i) = \frac{\exp(u_j)}{\sum_{v = 1}^{V} \exp(u_v)} = \frac{\exp(v_{1, w_i}^T v_{2, w_j})}{\sum_{v = 1}^{V} \exp(v_{1, w_i}^T v_{2, w_v})} \end{align*} $$注意其中的 $v_{1, w}$ 與 $v_{2, w}$ 分別表示單字 $w$ 的輸入與輸出向量
反向傳播 (Back Propagation)
給定單筆資料 $w_i$,其真實的下一個預測單字為 $w_j$,我們的目標是最大化 $\hat y_j = p (w_j | w_i)$,等價於最小化 $- \ln \hat y_j$,以此方向定義損失函數,定義
$$ \begin{align*} E = - \ln \hat y_j = - u_j + \ln \left[ \sum_{v = 1}^{V} \exp(u_v) \right] \end{align*} $$第 1 層梯度下降
接著開始反向傳播,從 $\bs u$ 的偏微分開始
$$ \begin{align*} \frac{\partial E}{\partial u_k} = - I (k = j) + \frac{\exp(u_k)}{\sum_{v = 1}^{V} \exp(u_v)} = - I (k = j) + \hat y_k \end{align*} $$使得
$$ \begin{align*} \frac{\partial E}{\partial \bs u} = \hat {\bs y} - \bs y = \bs H_2 \end{align*} $$接著對 $\bs W_2$ 進行偏微分,其結果 $\bs G_2$ 就是梯度下降 $\bs W_2$ 時所需的矩陣
$$ \begin{align*} \frac{\partial E}{\partial \bs W_2} = \frac{\partial E}{\partial \bs u} \frac{\partial \bs u}{\partial \bs W_2} = \bs h \bs H_2^T = \bs G_2 \end{align*} $$第 2 層梯度下降
再對 $\bs h$ 進行偏微分
$$ \begin{align*} \frac{\partial E}{\partial \bs h} = \frac{\partial E}{\partial \bs u} \frac{\partial \bs u}{\partial \bs h} = \bs W_2 \bs H_2^T = \bs H_1 \end{align*} $$最後對 $\bs W_1$ 進行偏微分,其結果 $\bs G_1$ 就是梯度下降 $\bs W_1$ 時所需的矩陣
$$ \begin{align*} \frac{\partial E}{\partial \bs W_1} = \frac{\partial E}{\partial \bs h} \frac{\partial \bs h}{\partial \bs W_2} = \bs x \bs H_1^T = \bs G_1 \end{align*} $$最後迭代方式即
$$ \begin{align*} \bs W_2^{(\text{new})} = \bs W_2^{(\text{old})} - \eta \bs G_2 \\ \bs W_1^{(\text{new})} = \bs W_1^{(\text{old})} - \eta \bs G_1 \end{align*} $$由於 $\bs x$ 是 one-hot encoding,只有 $x_i = 1$,因此 $\bs W_1$ 的迭代可以被簡化成只更新第 $i$ 列 (row),即
$$ \begin{align*} \bs v_{1, i}^{(\text{new})} = \bs v_{1, i}^{(\text{old})} - \eta \bs H_1 \end{align*} $$對於單字 $w_i$,最終會以輸入向量 $\bs v_{1, i}$ 作為其向量表達式
直觀上的解釋,$\bs H_1$ 是單字輸出向量 $\bs v_{2, j}$ 乘上預測誤差 $\hat y - \bs 1^{(j)}$ 所組成的向量。若輸出單字 $w_j$ 的機率被高估 (overestimated, $\hat y_j > y_j$),則輸入向量 $\bs v_{1, j}$ 會傾向遠離輸出向量 $\bs v_{2, j}$;相反的,若輸出單字 $w_j$ 的機率被低估 (underestimated, $\hat y_j < y_j$),則輸入向量 $\bs v_{1, j}$ 會傾向接近輸出向量 $\bs v_{2, j}$
給定文件後,設定輸入與預測的成對資料進行迭代,經過整個文本的迭代後,向量移動的效果會累積。我們可以想像單字 $w$ 的輸出向量會被周遭的單字來回拉動,就像有個吸引力會吸引 $w$ 周遭的單字;相對的,也可以假想輸入向量會受到輸出向量來回拉動,而這種來回拉動的力受到學習率 (learning rate) 與單字的共現性決定。並在經過多次迭代後,輸入與輸出向量最終會收斂至穩定
多輸入
在單輸入的假設中,單字的預測僅依靠前一個單字,且觀察權重 $\bs W_1$ 的迭代,同樣顯示出一次迭代僅對一個單字 $w_i$ 的輸入向量 $\bs v_{1, i}$ 進行更新
$$ \begin{align*} \bs v_{1, i}^{(\text{new})} = \bs v_{1, i}^{(\text{old})} - \eta \bs H_1 \end{align*} $$然而在實務上,單字預測應可依靠前後文做出更準確的推論,因此引入多輸入的 word to vector 模型。一般給定前後文的 $C$ 個單字,預測中心單字
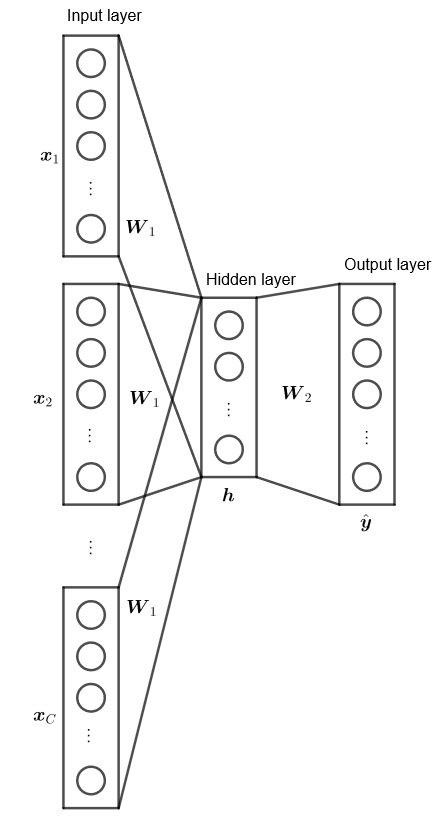
其建構方式唯一的改動是,設定輸入為 $C$ 的單字的 one-hot encoding 平均,使得輸入的向量改為
$$ \begin{align*} \bs h = \bs W_1^T \left( \frac{x_1 + x_2 + \cdots + x_C}{C} \right) \end{align*} $$即迭代的梯度平均分散至 $C$ 的單字上,其餘算式與推論維持原樣
$$ \begin{align*} \bs v_{1, w_i}^{(\text{new})} = \bs v_{1, w_i}^{(\text{old})} - \frac{1}{C} \eta \bs H_1, \quad i = \conti{C} \end{align*} $$Skip-Gram
Skip-gram 的建構方式與 CBOW 相反,給定中心詞後預測前後文,實務上是預測前後 $C$ 個單字。
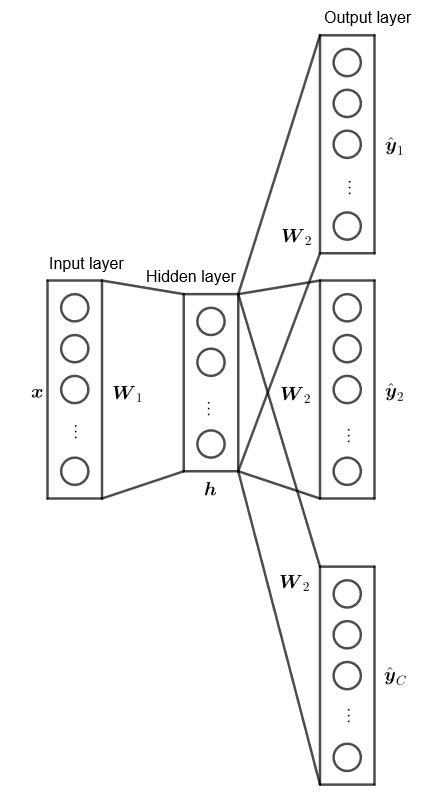
給定中心詞 $w_i$,其真實的前後文假設為 $w_{j_1}, w_{j_2}, \cdots, w_{j_C}$,此時目標便是最大化 $\hat y_{j_1}, \hat y_{j_2}, \cdots, \hat y_{j_C}$,等價於最小化 $-\ln (\hat y_{j_1} \hat y_{j_2} \cdots \hat y_{j_C})$,以此方向定義損失函數,定義
$$ \begin{align*} E & = - \ln (\hat y_{j_1} \hat y_{j_2} \cdots \hat y_{j_C}) = - \sum_{c = 1}^{C} u_{j_c} + \ln \left[ \sum_{v = 1}^{V} \exp (u_v) \right] \end{align*} $$使得
$$ \begin{align*} \frac{\partial E}{\partial \bs u} = \hat {\bs y} - \bs y = \bs H_2 \end{align*} $$後續所有偏微分與梯度下降公式完全相同,僅有 $\bs H_2$ 數值有些許不同
結論
多輸入 CBOW 等價於擴展 $\bs x$ 的單輸入 CBOW;Skip-gram 等價於擴展 $\bs y$ 的單輸入 CBOW;因此才會有類似的運算結構