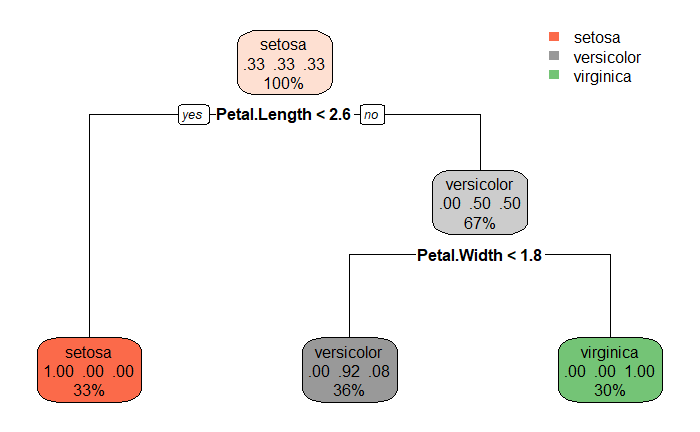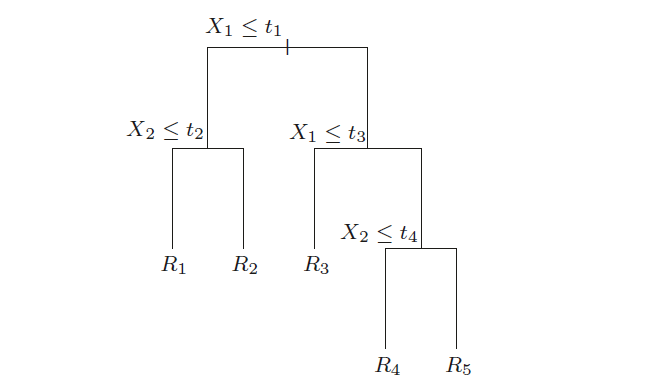
分類與回歸樹 (Classification and Regression Tree, CART)
簡介
分類與回歸樹 (Regression and classification tree, CART) 是一種基於決策樹的方式,將資料根據特徵切分成數個區域後,並對各自區域做預測,不只能用於類別型預測,也能用在非線性的預測問題。
- 分類樹:用於預測類別型資料,如顏色、性別。
- 回歸樹:用於預測數值型資料,如身高、體重。
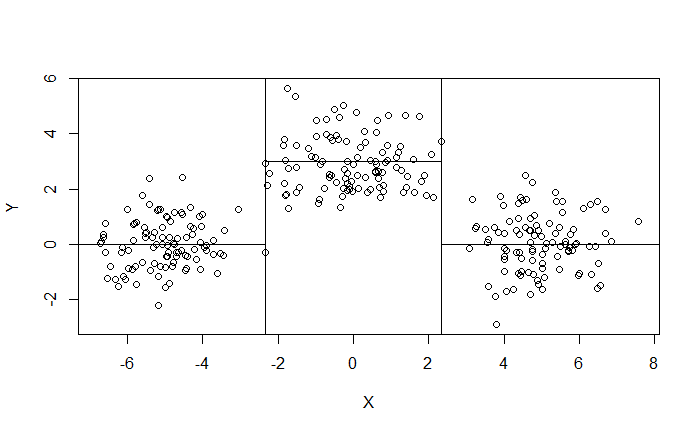
範例:給定 $X$ 預測 $Y$。
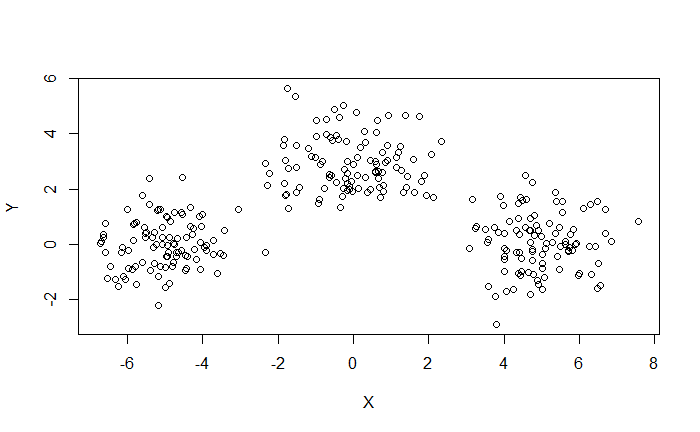
先將資料根據特徵切分成數個區塊。
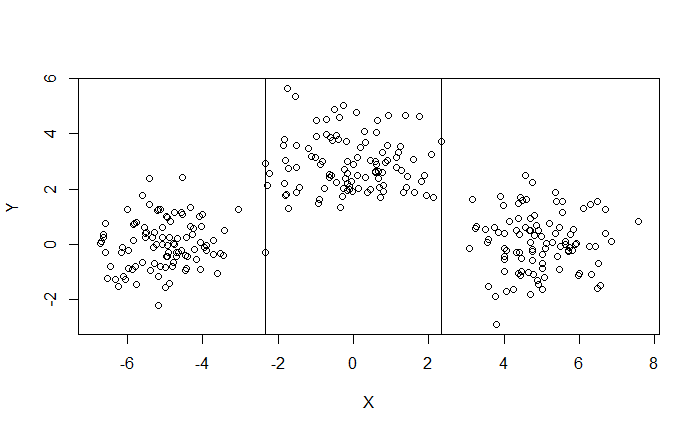
然後對各自區塊做預測。
而本文僅針對 recursive binary tree 討論,其兩大特色為
- 對區域做二元切分切成兩份 (binary) 子區域
- 每份子區域等於簡化後的問題,可以遞迴 (recursive) 的再次做切分
回歸樹
單維度切分
考慮二元切分與常數預測,每次切分考慮切割點 $t_m$ (或區域 $R_m$),與對該切分的預測值 $c_m$。
$$ \hat{y} = f (x) = \sum_{m = 1}^{M} c_m I (x \in R_m). $$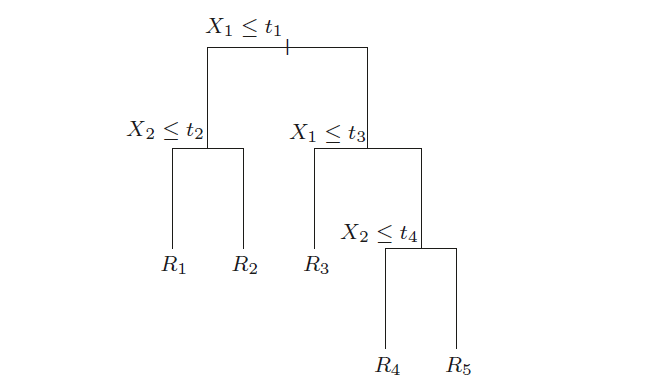
以最小化平方誤差合 (sum of squared error, SSE) 為目標決定預測值 $c_m$
$$ \begin{align*} c_m & = \argmin_{c_m} \sum_{i = 1}^{n} (y_i - \hat{y}_i)^2 \\ & = \argmin_{c_m} \sum_{x_i \in R_m} (y_i - c_m)^2 \\ & = \text{mean} (y_i | x_i \in R_m). \end{align*} $$下一步,根據切分點 $t$ 將資列切分成兩份
$$ \begin{align*} R_1 (t) = \{ X : X \leq t \} \quad \text{and} \quad R_2 (t) = \{ X : X > t \} \end{align*} $$此時同樣以最小化 SSE 為目標決定 $t$
$$ \begin{align*} \min_{t} \left[ \min_{c_1} \sum_{x_i \in R_1 (t)} (y_i - c_1)^2 + \min_{c_2} \sum_{x_i \in R_2 (t)} (y_i - c_2)^2 \right] \end{align*} $$我們不會考慮在 $t \in \mathbb R$,取而代之的是僅考慮有資料點取值得範圍。定義 $X_{(i)}$ 是 $X_1, X_2, \cdots, X_n$ 的排序統計量,我們從第二小的數值 $X_{(2)}$ 嘗試切分至第二大的數值 $X_{(n - 1)}$,並找到能最小化 SSE 的 $t$。
$$ \begin{align*} \min_{t \in X} \left[ \min_{c_1} \sum_{x_i \in R_1 (t)} (y_i - c_1)^2 + \min_{c_2} \sum_{x_i \in R_2 (t)} (y_i - c_2)^2 \right] \end{align*} $$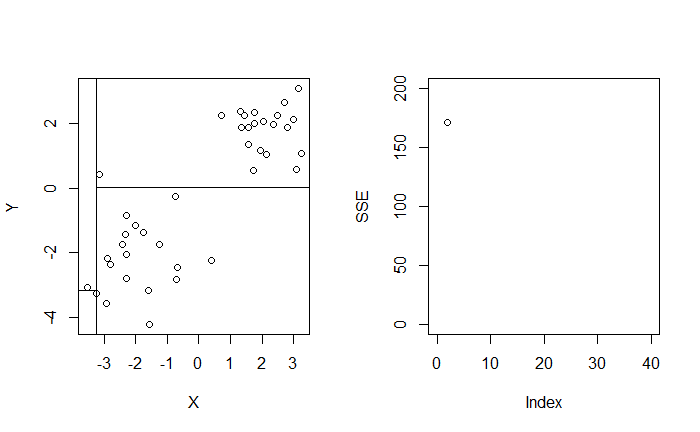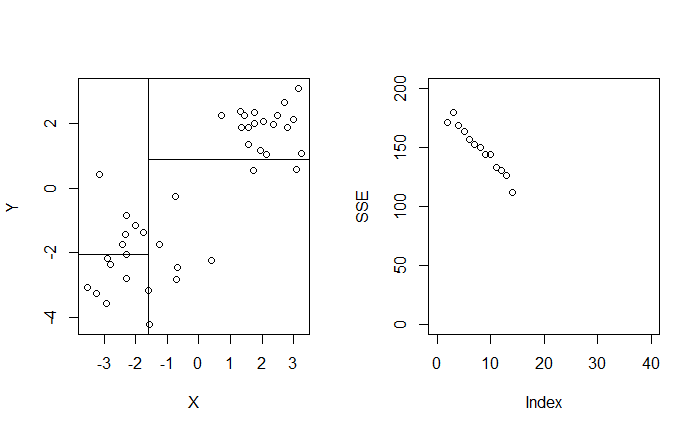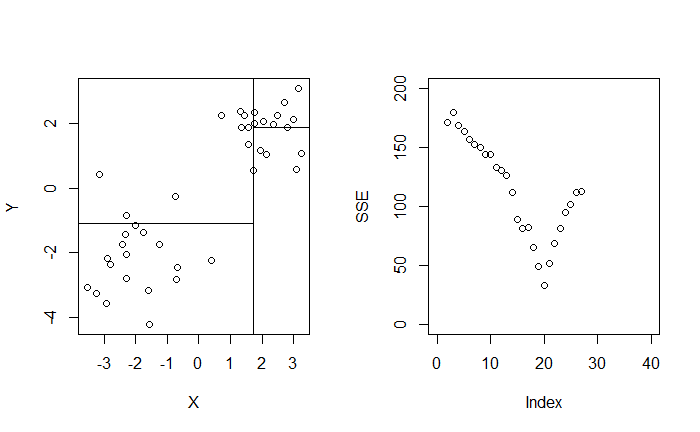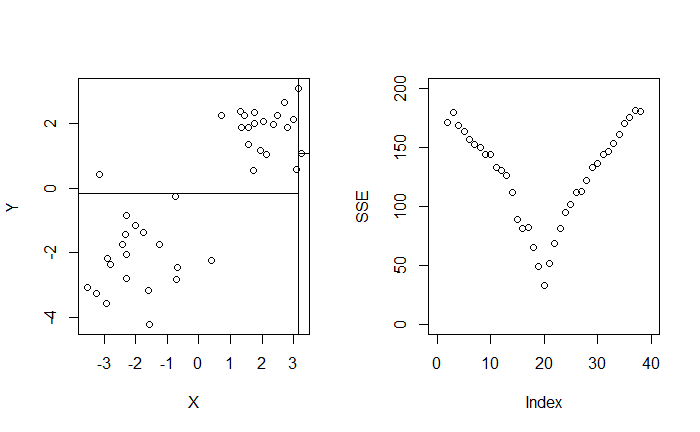
多維度切分
假設 $X \in \bb R^{n \times p}$,即每有 $n$ 筆資料,每筆資料有 $p$ 維度,現在考慮在第 $j$ 個維度將資料切分
$$ \begin{align*} R_1 (j, t) = \{ X : X_j \leq t \} \quad \text{and} \quad R_2 (j, t) = \{ X : X_j > t \}. \end{align*} $$同樣是尋找能讓 SSE 最小化的 $j$ 與 $t$
$$ \begin{align*} \min_{j, t} \left[ \min_{c_1} \sum_{x_i \in R_1 (j, t)} (y_i - c_1)^2 + \min_{c_2} \sum_{x_i \in R_2 (j, t)} (y_i - c_2)^2 \right]. \end{align*} $$讓 $j$ 從 $1$ 嘗試到 $p$,更精確地說
$$ \begin{align*} \min_{j \in \{1, 2, \cdots, p\}} \min_{t \in X_j} \left[ \min_{c_1} \sum_{x_i \in R_1 (j, t)} (y_i - c_1)^2 + \min_{c_2} \sum_{x_i \in R_2 (j, t)} (y_i - c_2)^2 \right]. \end{align*} $$用 iris 作為示範 (只考慮數值部分)
| Sepal.Length ($X_1$) | Sepal.Width ($X_2$) | Petal.Length ($X_3$) | Petal.Width ($Y$) |
|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 |
| 4.9 | 3.0 | 1.4 | 0.2 |
| 4.7 | 3.2 | 1.3 | 0.2 |
| 4.6 | 3.1 | 1.5 | 0.2 |
| 5.0 | 3.6 | 1.4 | 0.2 |
| 5.4 | 3.9 | 1.7 | 0.4 |
| 4.6 | 3.4 | 1.4 | 0.3 |
| 5.0 | 3.4 | 1.5 | 0.2 |
| … | … | … | … |
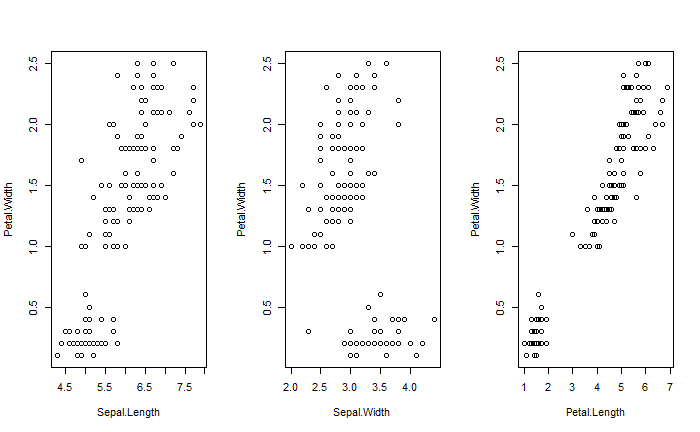
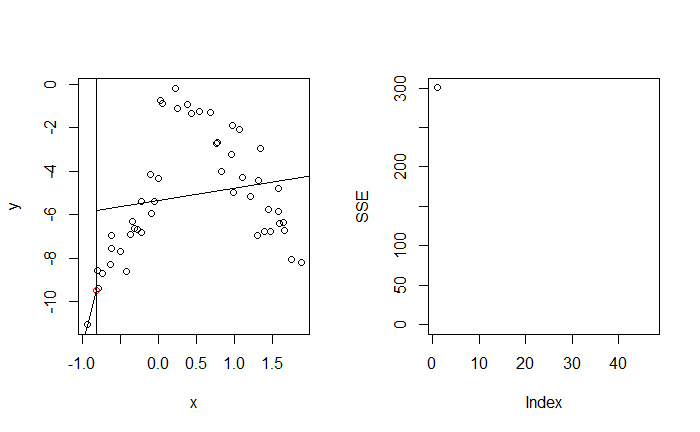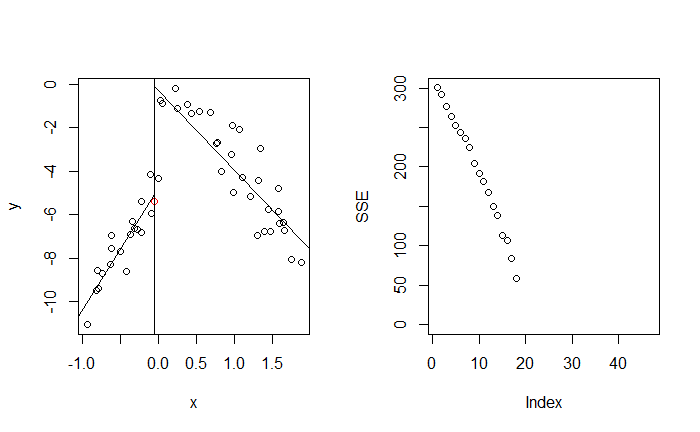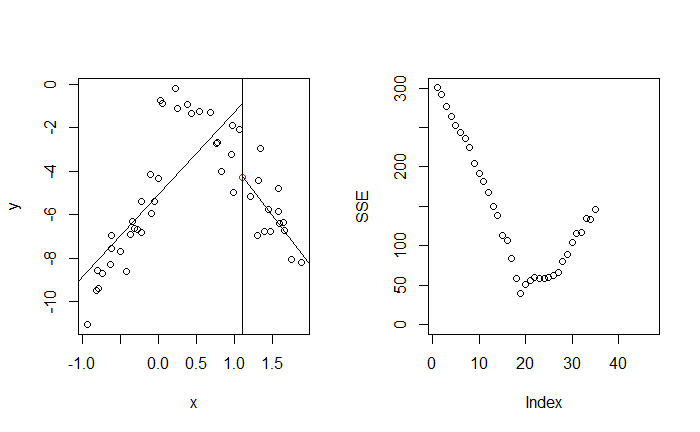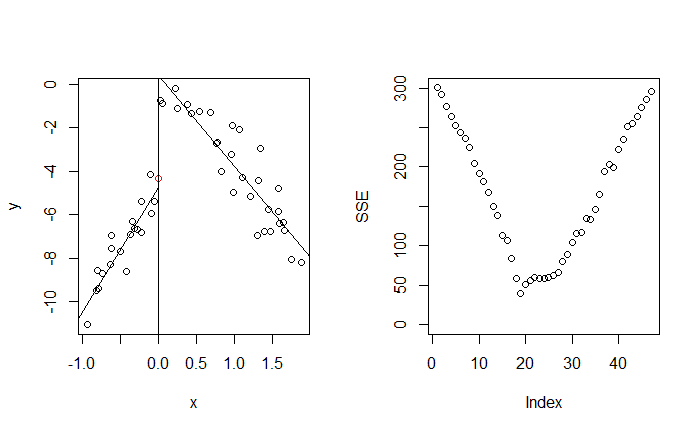
從 $j = 1$ 開始,即嘗試切分 $X_1$
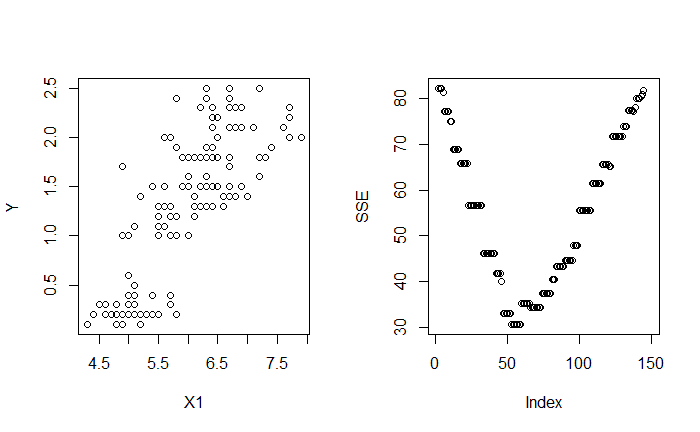
相似的,對 $X_2$ 與 $X_3$ 做切分
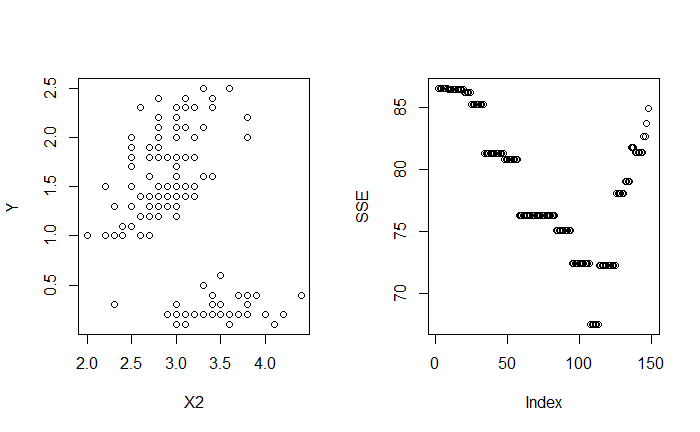
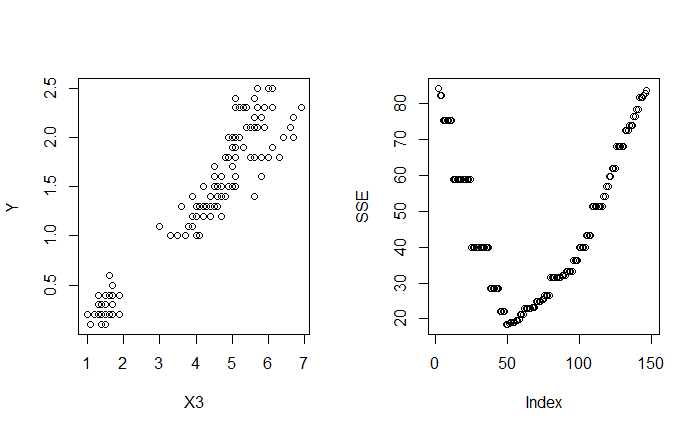
最終目標是找到 $j$ 與 $t$ 能最小化 SSE
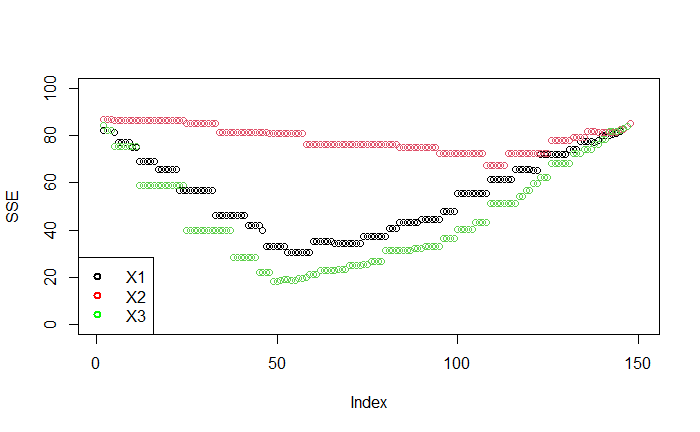
而最好的切點落在 $(j, t) = (3, 1.9)$,即
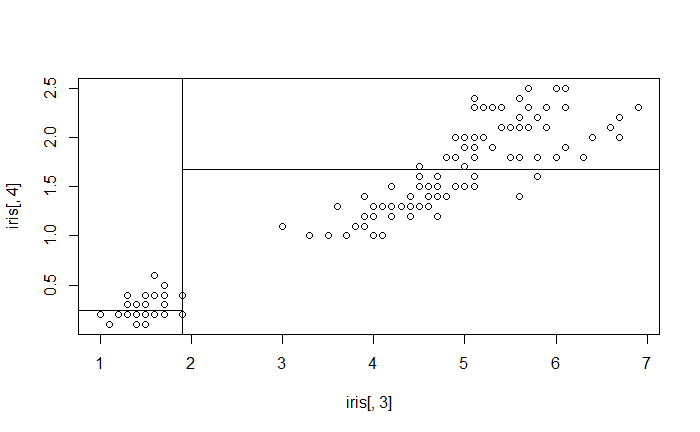
現在將 $R_1$ 的點以紅色標記。
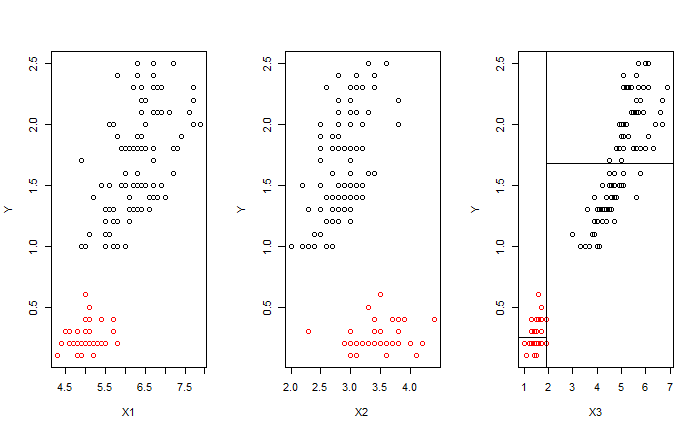
下一步將 $R_1$ 的點移除,剩下的將是 $R_2$ 的點。
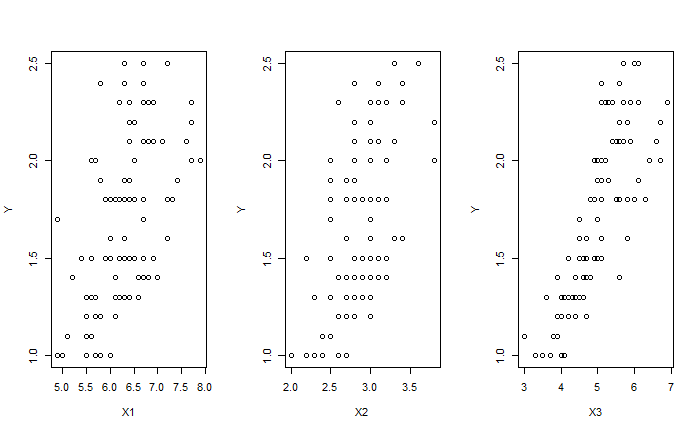
我們能對剩下的資料再次進行切分
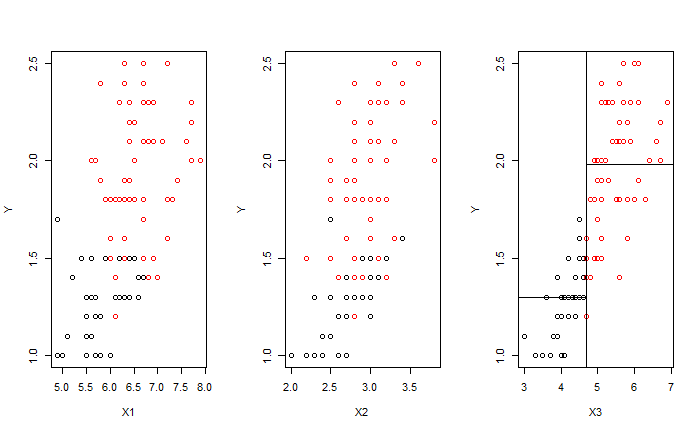
並不斷重複這個過程,直到切分 SSE 沒有明顯的最小值,或資料已經切分至太細。
複雜度標準 (cost complexity criterion)
僅追求最小化 SSE 會導致切分區域過多,即"樹非常大",會導致 over fitting;相對的,過小的樹可能會沒辦法抓到資料的特徵。因此定義 複雜度標準 (cost complexity criterion),概念是同時平衡"錯誤量"與"樹的複雜度"。
令 $|T|$ 是 $T$ 這棵樹的節點數量,並令
給定一數 $\alpha \geq 0$,定義
我們的目標是最小化這個複雜度標準,其中的 $\alpha$ 是個調整參數,他會懲罰那些過大過複雜的樹,即"$\alpha$ 越大,樹越小"。對 $\alpha$ 的選擇,可考慮最小化 5-cross validation sum of squares。
分類樹
對類別型變數 (例如:顏色、性別) SSE 不再可用,若假設 $y$ 有 $K$ 種可能的分類,標作 $\\{1, 2, \cdots, K\\}$,我們會用純度來描述 $Q_m (T)$,並定義 $p_{mk}$ 是第 $m$ 個區域中第 $k$ 種類所佔的比例
最終根據節點 $m$ 中所佔比例最高的種類當成最終預測
下列提供數種不同純度標準 $Q_m (T)$
錯分率 (misclassification error):
$$ \begin{align*} \frac{1}{N_m} \sum_{x_i \in R_m} I (y_i \ne k(m)) = 1 - \hat p_{m k (m)}. \end{align*} $$Gini index:
$$ \begin{align*} \sum_{k \ne l} \hat p_{m k} \hat p_{m l} = \sum_{k = 1}^{K} \hat p_{m k} (1 - \hat p_{m k}). \end{align*} $$Cross-entropy or deviance:
$$ \begin{align*} - \sum_{k = 1}^{K} \hat p_{m k} \ln (\hat p_{m k}). \end{align*} $$
其他建樹方案
要建立決策樹,我們有兩步需要考慮
- 如何將資料切分
- 如何對切分的區域做預測
線性組合切法
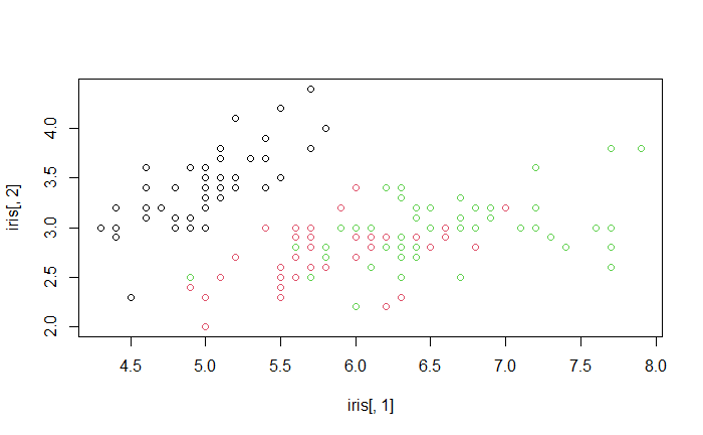
在一般的切分中僅考慮 $X_j < t$,但可以考慮資料的線性組合切割 $\sum_{j = 1}^{p} a_j X_j < t$,而其中的係數 $a_j$ 與切分點 $t$ 是以最小化 Gini index 為目標所決定的。
例如:iris的前兩個維度能看到完美切分點。
回歸預測
不僅可以做常數的預測,也能對切分出來的區域單獨做回歸,而最終目標仍是最小化 cost complexity criterion (或 SSE,當 $\alpha = 0$ 的時候)。
R 語言範例
載入必要 packages
library(rpart) # CART
library(rpart.plot) # CART plot
library(caret) # model training
library(dplyr) # %>%
採樣
# sampling
set.seed(0)
trainIndex = createDataPartition(iris$Species, p = 0.7, list = FALSE)
trainData = iris[trainIndex, ]
testData = iris[-trainIndex, ]
用 caret 的 train 訓練 CART 模型
# cart
cart = train(Species ~ .,
data = trainData,
method = "rpart",
trControl = trainControl(method = "cv", number = 10), # k-Fold cross validation
tuneLength = 10) # Try possible number of parameter
模型修剪,平衡錯誤率與樹大小
# complexity parameter prune
pruned_cart = prune(cart$finalModel, cp = 0.01)
混淆矩陣表現
# confusion matrix
predictions = predict(pruned_cart, testData, type = "class")
confusionMatrix(predictions, testData$Species)
繪製模型結果