arXiv 爬蟲
引言
封面是我難得動手畫的圖,原本想畫恐龍,畢竟技術上來說恐龍也是種蜥蜴;但問題也出在技術上來說,我連高中美術都沒過。希望這隻蜥蜴能順利保我過碩士論文。
總之,這次的目標是抓取 arXiv 中關於 Machine Learning 的論文資訊
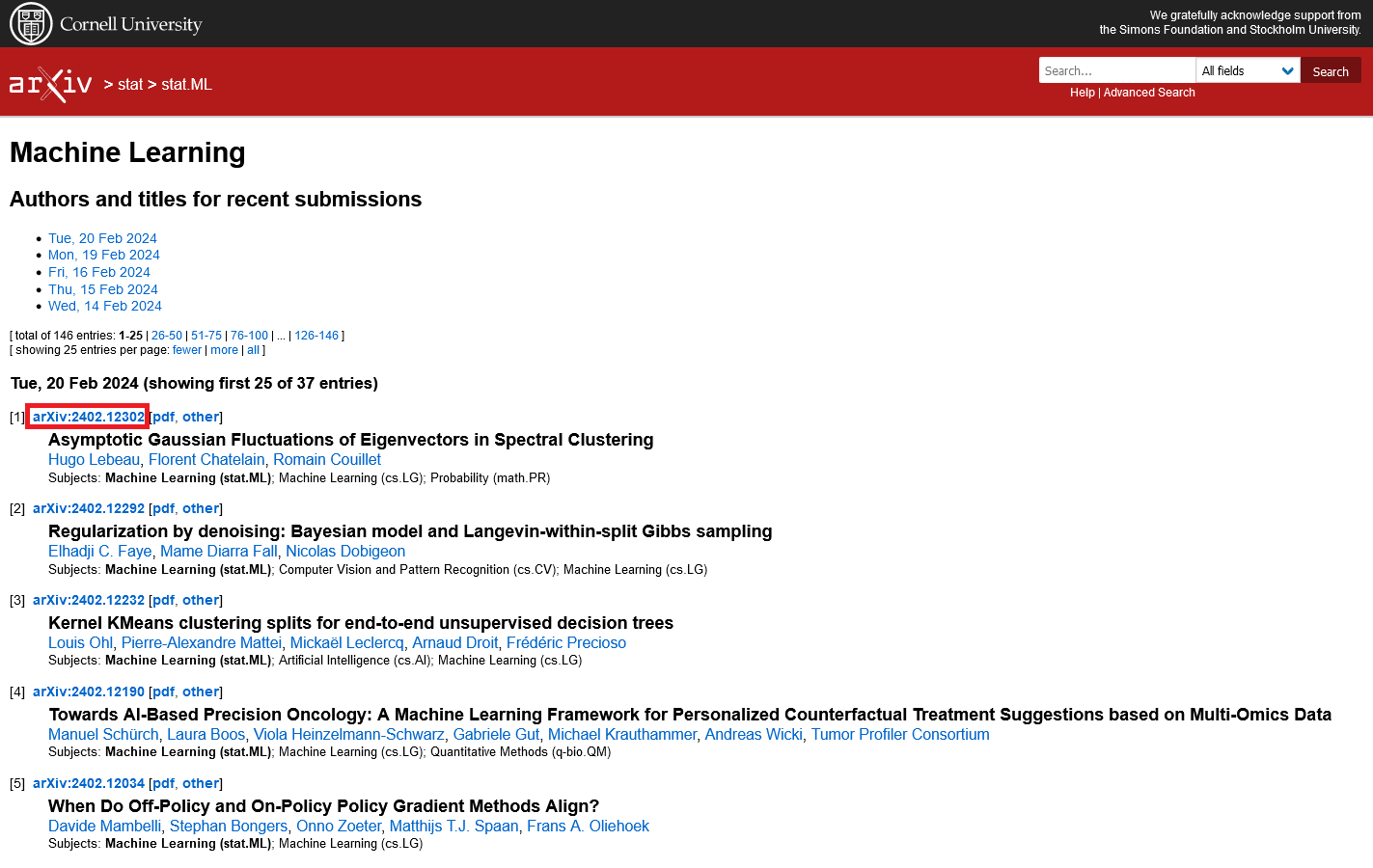
任選一篇文章進入後,抓取 title 和 abstract,紅框部分。
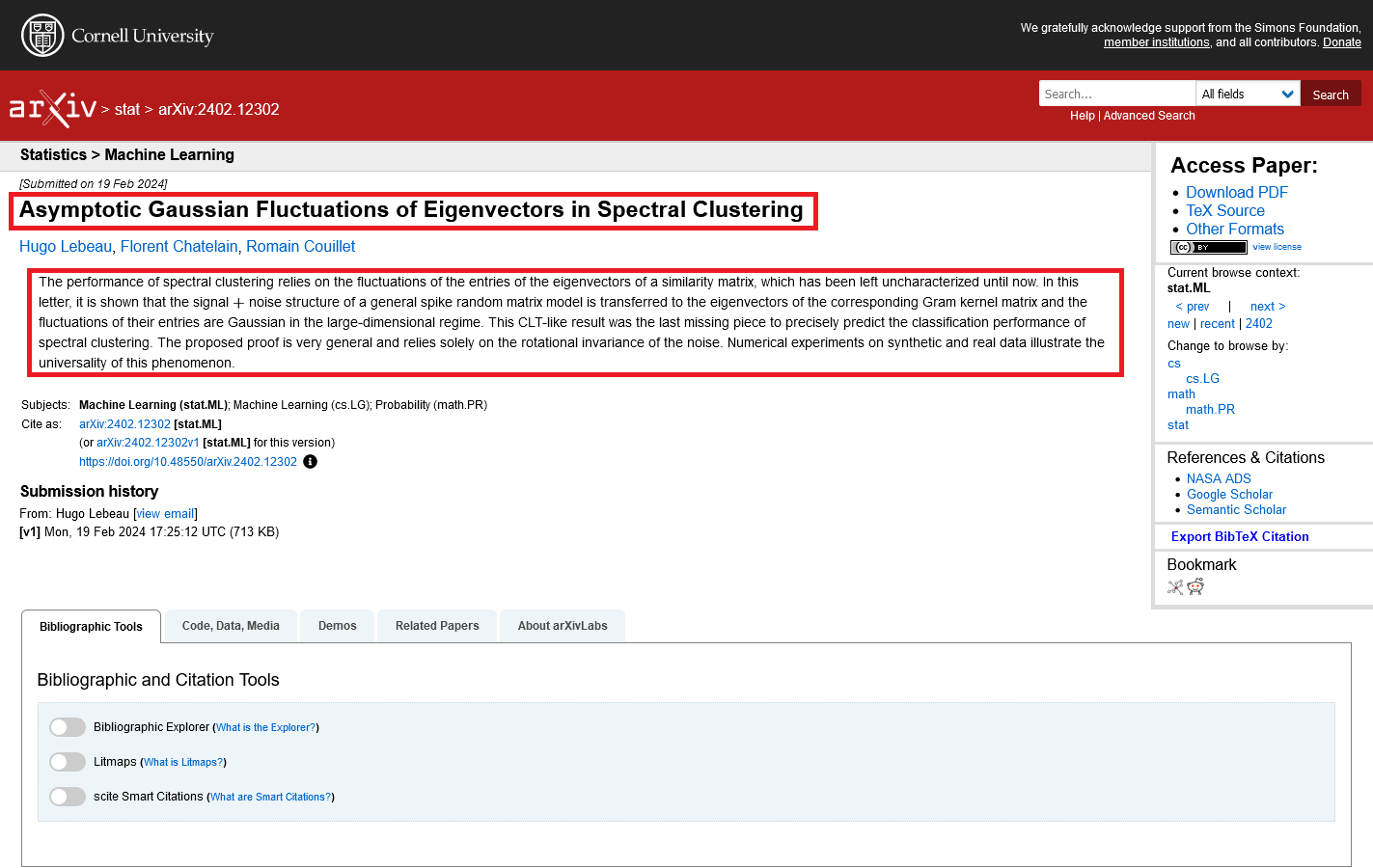
因此目標設定為
- 在主頁面找到內文連結
- 連結到內文,獲取 title 和 abstract
主頁面爬蟲
在 Python 安裝 requests 套件對網頁發出訪問請求、BeautifulSoup 來解構擷取架構 (以下簡稱bs4)、lxml 解構網頁架構。
pip install requests
pip install BeautifulSoup4
pip install lxml
安裝完成後,對 arXiv 做出訪問請求
import requests # 發送網頁請求
from bs4 import BeautifulSoup # 網頁工具
import time # 計時工具
import csv # 儲存檔案
# arxiv machine learning topic
url = "https://arxiv.org/list/stat.ML/pastweek?show=100"
html = requests.get(url) # 向指定網頁發出訪問請求
html.encoding = 'UTF-8' # 用UTF-8格式讀取網站
bs = BeautifulSoup(html.text, 'lxml') # 用lxml讀取
print(bs)
bs 顯示出來的資訊就是網站的 html 架構,在網頁中按下 F12 會看到一樣的東西
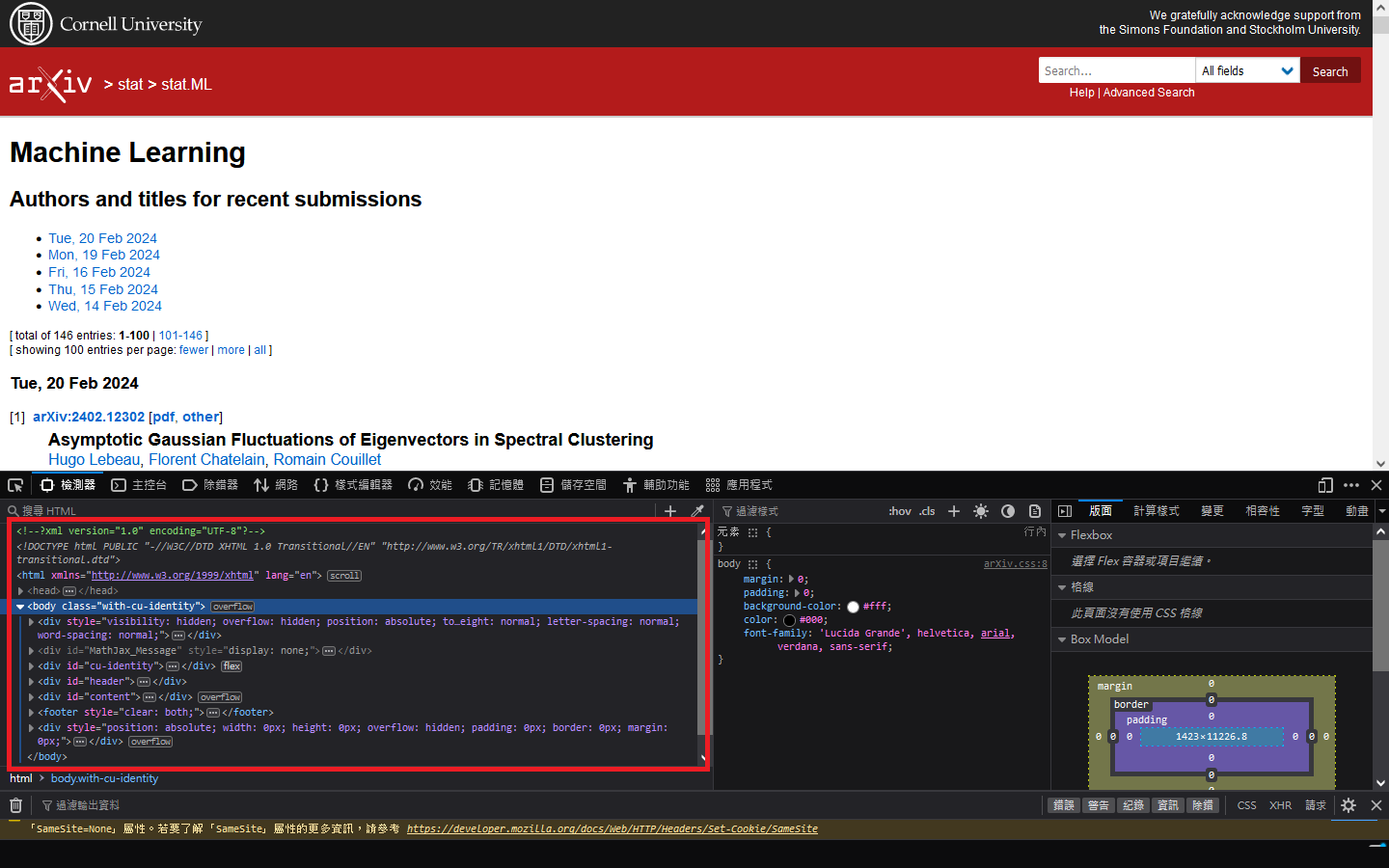
點選物件檢視器
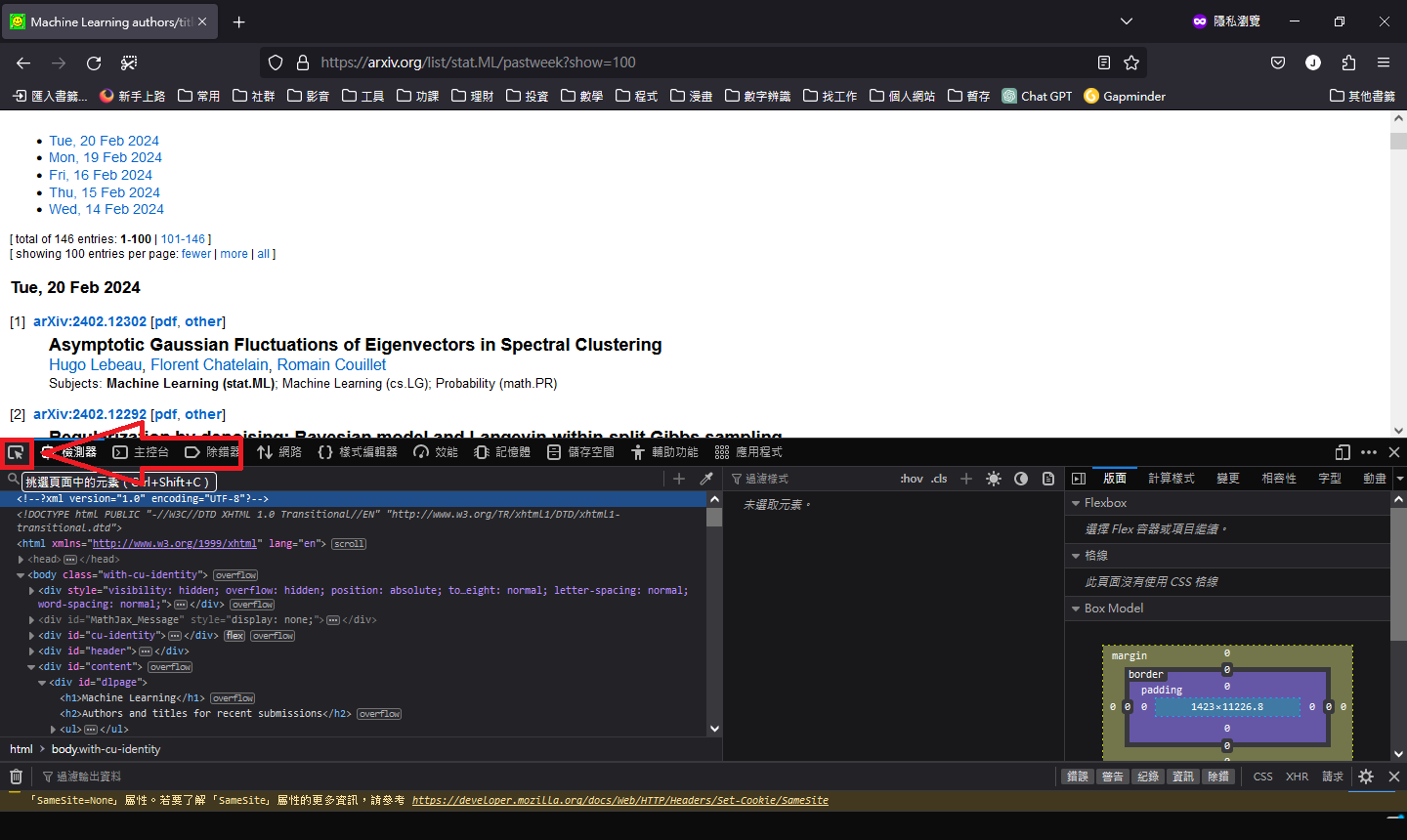
任選一個內文的連結
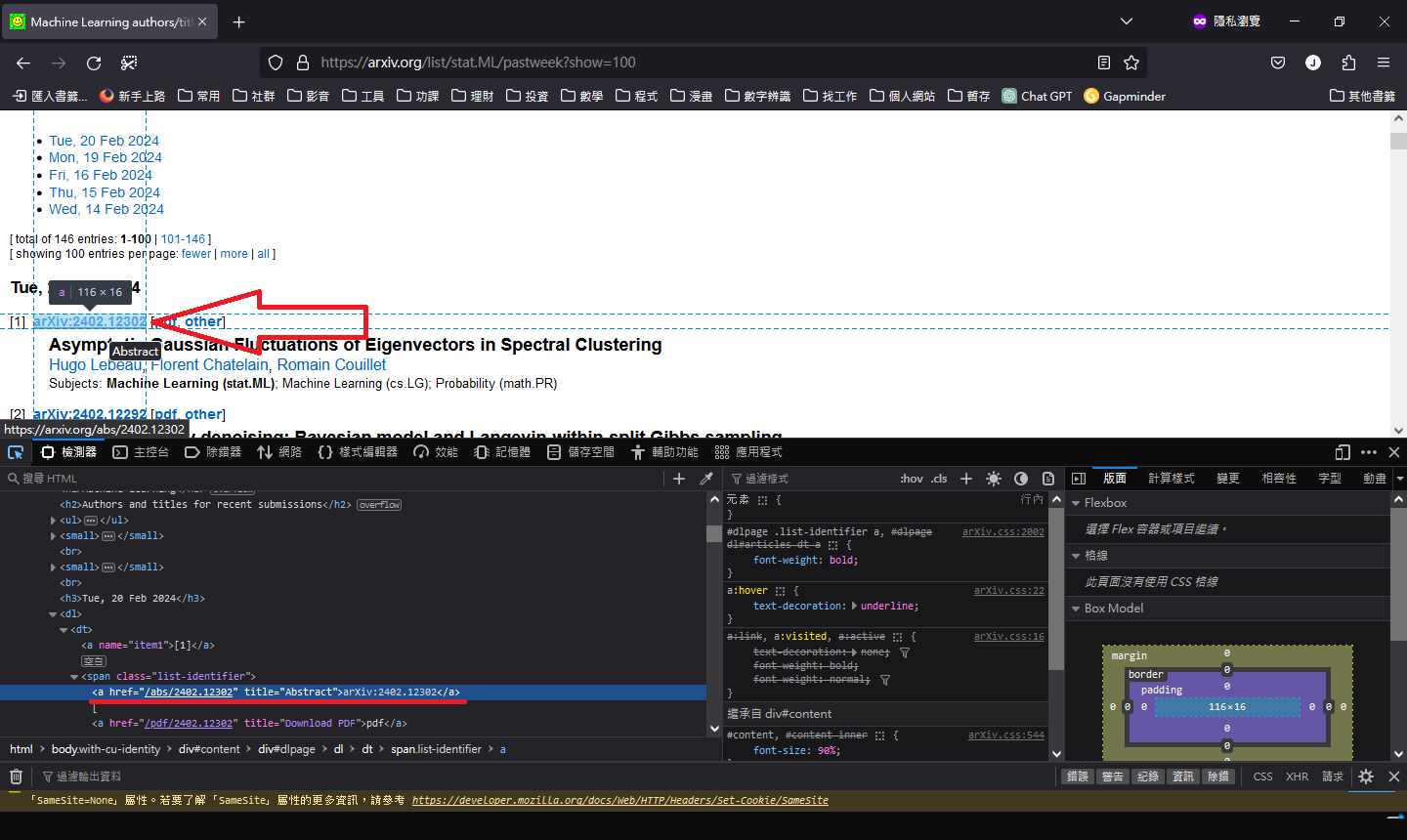
會發現這個物件有如下特徵 title="Abstract"
<a href="/abs/2402.12302" title="Abstract">arXiv:2402.12302</a>
其中的 href 就是前往內文的連結,網址通向
https://arxiv.org/abs/2402.12302
這就是要蒐集的目標,用 find_all 把 title="Abstract" 全部蒐集下來
identifier = bs.find_all(title = 'Abstract') # 尋找指定 class name 的資料
n = len(identifier)
for i in range(n):
print(identifier[i])
會蒐集到
<a href="/abs/2402.12302" title="Abstract">arXiv:2402.12302</a>
<a href="/abs/2402.12292" title="Abstract">arXiv:2402.12292</a>
<a href="/abs/2402.12232" title="Abstract">arXiv:2402.12232</a>
用 identifier[i].text 選取 <a> 這邊的資訊 </a>,也就是 arXiv:2402.12232,再每個元素一一處理
for i in range(n):
identifier[i] = "https://arxiv.org/abs/" + identifier[i].text[6:]
for i in range(n):
print(identifier[i])
轉換成
https://arxiv.org/abs/2402.12302
https://arxiv.org/abs/2402.12292
https://arxiv.org/abs/2402.12232
內文爬蟲
現在的 identifier 蒐集了通往內文的網址,現在觀察內文的特徵
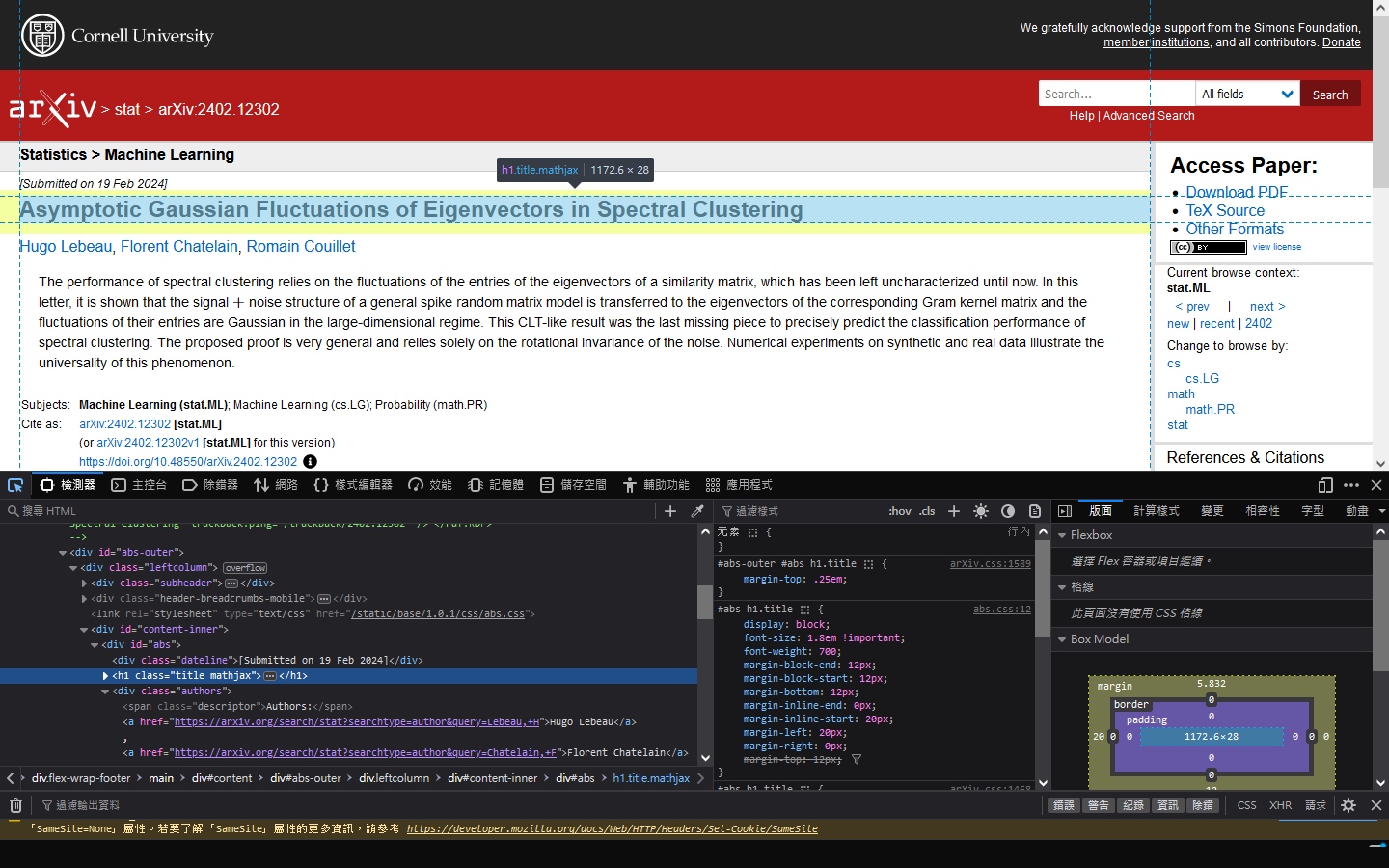
會發現標題的 class 是 title mathjax,而簡介的 class 則是 abstract mathjax。在此設計一個函式是針對內文的資訊,功能是給定內文網址,回傳內文的 title 和 abstract。
# 獲取文章資訊
def get_info(url):
html = requests.get(url) # 向指定網頁發出訪問請求
html.encoding = 'UTF-8' # 用UTF-8格式讀取網站
bs = BeautifulSoup(html.text, 'lxml') # 用lxml讀取
# 列印出結果
# print(bs)
title = bs.find(class_ = 'title mathjax').text[6:]
# print(title)
abstract = bs.find(class_ = 'abstract mathjax').text[10:-5]
# print(abstract)
return {"title": title, "abstract": abstract}
特別注意,過高速的網頁訪問可能會被視為 DDOS 攻擊,建議降低訪問頻率,例如用 time.sleep(5) 設定每5秒訪問一個內文,並用 artical 儲存蒐集到的資訊
artical = []
for i in range(n):
artical.append(get_info(identifier[i]))
time.sleep(5)
print("current", i + 1, "/", n)
儲存 csv 檔案
用 csv 這包就能簡單做到
csv_file = "articles.csv" # 儲存的檔案名稱
with open(csv_file, "w", newline="", encoding="utf-8") as file:
# 這邊的 fieldnames 設定成前面 artical 設定的引數名稱
writer = csv.DictWriter(file, fieldnames=["title", "abstract"])
# 逐行寫入資料
writer.writeheader()
for each_article in artical:
writer.writerow(each_article)
print("寫入完成", csv_file)
最後就能在這個 python 檔案位置獲得一個名為 articles.csv 的資料,裏頭就儲存了文章的 title 和 abstract。