單變數線性回歸變異數分析 (Analysis of Variance, ANOVA)
公式
- $SSE = \sum_{i = 1}^{n} (Y_i - \hat Y_i)^2$
- $SSR = \sum_{i = 1}^{n} (\hat Y_i - \ol Y)^2$
- $SSTO = \sum_{i = 1}^{n} (Y_i - \ol Y)^2 = SSE + SSR$
- $MSE = SSE / (n − 2)$
- $MSR = SSE / 1$
- $F^* = MSR / MSE$
- $\text{P-value} = P (F^* \leq F_{1, n - 2})$
變異數分析 (Analysis of Variance, ANOVA)
定義
- Sum of Square Total (SSTO):評估資料變異數的總量
- Sum of Square Regression (SSR):評估模型變異數的總量
- Sum of Square Errors (SSE):評估殘差 (residual) 的總量
因為
$$ \begin{align*} \sum_{i = 1}^{n} (Y_i - \ol Y)^2 = \sum_{i = 1}^{n} (Y_i - \hat Y_i)^2 + \sum_{i = 1}^{n} (\hat Y_i - \ol Y)^2 \end{align*} $$所以可以寫成
$$ \begin{align*} SSTO = SSE + SSR \end{align*} $$自由度 (Degree of Freedom, df)
給個自由度 (degree of freedom, df) 的範例是
$$ X + Y + Z = 0 $$決定 $X$ 與 $Y$ 後,$Z$ 就喪失選擇的自由,因為他必須滿足上述等式,所以這個方程的解可以被寫為
$$ (X, Y, Z) = (X, Y, - X - Y) $$雖然有 $3$ 個變數,但實則只有 $2$ 個變數就自由決定,可以理解為自由度是 $2$。若現在方程滿足
$$ \left\lbrace \begin{array}{lcl} X + Y + Z & = & 0 \\ X + Y & = & 0 \end{array} \right. $$解為
$$ (X, Y, Z) = (X, -X, 0) $$只有 $1$ 個變數能自由決定,因此自由度為 $1$。
均方 (Mean Squares, MS)
因為 $Y$ 滿足
$$ \begin{align*} \sum_{i = 1}^{n} (Y_i - \ol Y) = 0 \end{align*} $$解被寫為
$$ \begin{align*} \left( \contia{Y}{n - 1}, - \sum_{i = 1}^{n - 1} Y_i \right) \end{align*} $$因此
$$ \begin{align*} SSTO = \sum_{i = 1}^{n} (Y_i - \ol Y)^2 \end{align*} $$自由度為 $n - 1$。相似的,用 $\hat Y$ 估計 $\beta_0 + \beta_1 X$,需要兩個自由度估計 $b_0$ 與 $b_1$,因此
$$ \begin{align*} SSE = \sum_{i = 1}^{n} (Y_i - \hat Y)^2 \end{align*} $$自由度為 $n - 2$。而
$$ \begin{align*} SSR = \sum_{i = 1}^{n} (Y_i - \ol Y)^2 \end{align*} $$自由度為 $1$。定義
- Mean of Square Regression (MSR)
- Mean of Square Errors (MSE)
寫成
| 來源 | SS | df | MS |
|---|---|---|---|
| Regression | $\dps SSR = \sum_{i = 1}^{n} (\hat Y_i - \ol Y)^2$ | $1$ | $\dps MSR = \frac{SSR}{1}$ |
| Error | $\dps SSE = \sum_{i = 1}^{n} (Y_i - \hat Y_i)^2$ | $n - 2$ | $\dps MSE = \frac{SSE}{n - 2}$ |
| Total | $\dps SSTO = \sum_{i = 1}^{n} (Y_i - \ol Y)^2$ | $n - 1$ |
F-test 與 P-value
在上一章節討論過
$$ \begin{align*} H : \beta_1 = 0 \quad \text{vs} \quad A : \beta_1 \ne 0 \end{align*} $$的檢定量為
$$ \begin{align*} t^* = \frac{b_1}{s (b_1)} \sim Z / \sqrt{ \frac{\chi_{n - 2}^2}{n - 2} } \end{align*} $$取平方後
$$ \begin{align*} F^* & = (t^*)^2 = \frac{b_1^2}{s^2 (b_1)} = \frac{SSR / \sigma^2}{1} / \frac{SSE / \sigma^2}{n - 2} = \frac{MSR}{MSE} \end{align*} $$根據 Cochran’s theorem,$MSR \sim \chi_1^2$ 獨立於 $MSE \sim \chi_{n - 2}^{2}$,因此
$$ \begin{align*} F^* \sim \frac{\chi_{1}^2}{1} / \frac{\chi_{n - 2}^2}{n - 2} \sim F_{1, n - 2} \end{align*} $$此檢定在單變數回歸中,$t$ 與 $F$ 檢定的結果是相同的,定義
$$ \begin{align*} \text{P-value} = P (F^* \leq F_{1, n - 2}) \end{align*} $$且 P-value $\in [0, 1]$,在給定 $\alpha$ 的信心水準下,檢定
$$ \begin{align*} H : \beta_1 = 0 \quad \text{vs} \quad A : \beta_1 \ne 0 \end{align*} $$的標準是
- 若 P-value $\leq \alpha$ 推論 $A$
- 若 P-value $> \alpha$ 推論 $H$
一般來說,我們希望 $X$ 能對 $Y$ 的預測做出貢獻,即 $\beta_1 \ne 0$,因此在實際問題中,P-value 越接近 $0$ 是比較希望見到的結果。
決定係數 (Coefficient of Determination, $R^2$)
引進一種用於評估模型解釋效力的方式,稱為決定係數 (coefficient of determination)
$$ \begin{align*} R^2 = \frac{SSR}{SSTO} = 1 - \frac{SSE}{SSTO} \end{align*} $$由於 $SSTO = SSE + SSR$ 且 $SSR \geq 0$,因此 $R^2 \in [0, 1]$。$R^2$ 所描述的性質是為
越大的 $R^2$,有越多的 $Y$ 的變異數能被 $X$ 決定
討論 $R^2$ 的兩個極端值
- $R^2 = 1$ 發生在 $SSE = 0$,也就是所有的真實的 $Y$ 與預測的 $\hat Y$ 都相同,即 $Y_i = \hat Y_i$,對任意 $i = \conti{n}$。
- $R^2 = 0$ 發生在 $SSR = 0$,也就是 $X$ 的出現對於預測 $Y$ 沒有任何幫助,即 $b_1 = 0$ 與 $\hat Y_i = \ol Y$,對任意 $i = \conti{n}$。
然而 $R^2$ 的使用也帶也些限制
- $R^2 \approx 1$ 不直接推論到預測很好
- $R^2 \approx 0$ 不直接推論到 $X$ 與 $Y$ 無關
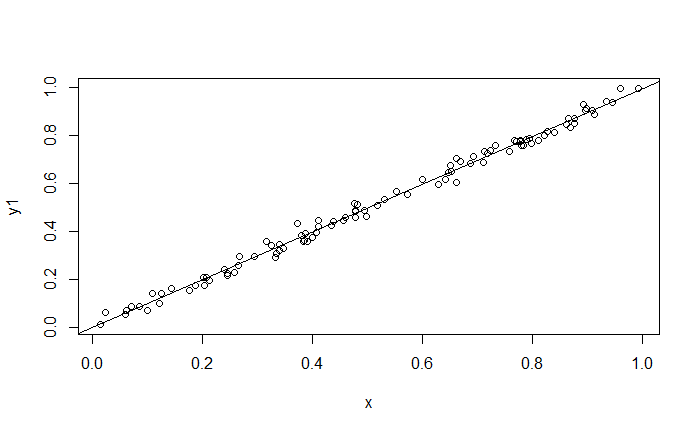
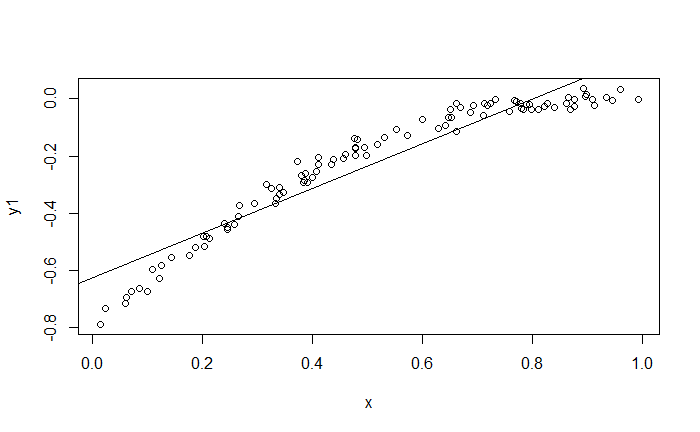
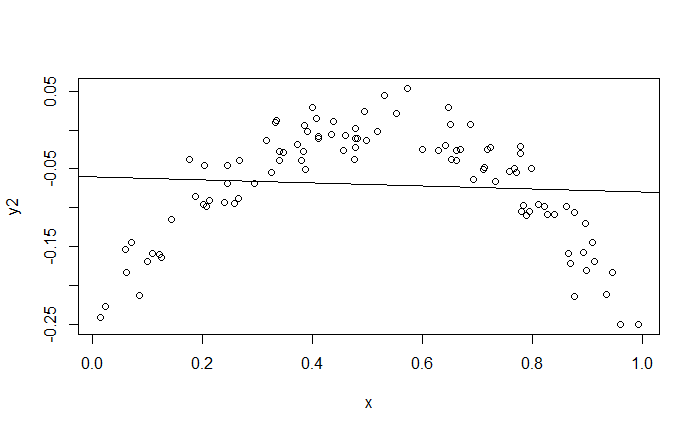
問題出在"可能存在非線性關係",下列兩張圖的 $R^2$ 分別是 $0.9$ 與 $0.005$,個別存在一定程度的非線性關係。第一張圖線性預測會帶有偏誤;而第二張圖顯示出 $X$ 與 $Y$ 存在關係,但不是線性關係。
R 語言程式範例
資料範例 Stat 501 的 Example 3-1: Hospital Infection Data,用 Stay ($X$) 預測 InfctRsk ($Y$)。
# 讀檔案
data = read.table("hospitalinfct_reg1and2.txt", # 資料名稱
header = T # 設定第一列為名稱
)
# 查看讀到結果
data
讀到的結果會呈現
ID Stay Age InfctRsk Culture Xray Beds MedSchool Region Census
5 11.20 56.5 5.7 34.5 88.9 180 2 1 134
10 8.84 56.3 6.3 29.6 82.6 85 2 1 59
11 11.07 53.2 4.9 28.5 122.0 768 1 1 591
13 12.78 56.8 7.7 46.0 116.9 322 1 1 252
18 11.62 53.9 6.4 25.5 99.2 133 2 1 113
用 lm (linear model) 訓練模型
fm = lm(InfctRsk ~ Stay, data) # 用 Stay 預測 InfctRsk
Summary
用 summary 查看模型訓練的結果
summary(fm)
結果
Call:
lm(formula = InfctRsk ~ Stay, data = data)
Residuals:
Min 1Q Median 3Q Max
-2.6145 -0.4660 0.1388 0.4970 2.4310
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -1.15982 0.95580 -1.213 0.23
Stay 0.56887 0.09416 6.041 1.3e-07 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.024 on 56 degrees of freedom
Multiple R-squared: 0.3946, Adjusted R-squared: 0.3838
F-statistic: 36.5 on 1 and 56 DF, p-value: 1.302e-07
解析
| Estimate | Std. Error | t value | Pr(>|t|) | |
|---|---|---|---|---|
| (Intercept) | $b_0$ | $s (b_0)$ | $t_0^* = b_0 / s (b_0)$ | $P(t_{n - 2} \geq \|t_0^*\|)$ |
| $X$ | $b_1$ | $s (b_1)$ | $t_1^* = b_1 / s (b_1)$ | $P(t_{n - 2} \geq \|t_1^*\|)$ |
- Residual standard error: $\sqrt{MSE} = \sqrt{SSE / (n - 2)}$ on $n - 2$ degrees of freedom
- Multiple R-squared: $R^2 = SSR / SSTO = 1 - SSE / SSTO$
- Adjusted R-squared: $R_a^2$ 用於多變數線性回歸,先不討論
- F-statistic: $F^* = (t_1^*)^2 = MSR / MSE$ on $1$ and $n - 2$ DF
- p-value: $P (F^* \leq F_{1, n - 2})$
其中的 Pr (>|t|) 為檢定量
$$ P(t_{n - 2} \geq |t_j^*|) = P (-|t_j^*| \leq t_{n - 2} \leq |t_j^*|) $$所對應的假設檢定是
$$ H : \beta_j = 0 \quad \text{vs} \quad A : \beta_j \ne 0 $$ANOVA
用 anova 查看變異數分析 (analysis of variance)
anova(fm)
結果
Analysis of Variance Table
Response: InfctRsk
Df Sum Sq Mean Sq F value Pr(>F)
Stay 1 38.306 38.306 36.496 1.302e-07 ***
Residuals 56 58.776 1.050
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
解析
| Df | Sum Sq | Mean Sq | F value | Pr(>F) | |
|---|---|---|---|---|---|
| $X$ | 1 | $SSR$ | $MSR = SSR / 1$ | $F^* = MSR / MSE$ | $P (F_{1, n - 2} > F^*)$ |
| Residuals | $n - 2$ | $SSE$ | $MSE = SSE / (n - 2)$ |
在單變數的 $t$ 與 $F$ 檢定都是檢定
$$ H : \beta_1 = 0 \quad \text{vs} \quad A : \beta_1 \ne 0 $$因此單變數回歸中 p-value、summary 中的 Pr (>|t|) 與 anova 中的 Pr (>F) 都是相同的。
參考資料
- 書籍:Applied linear statistical models. NETER, John, et al. 1996.
- 網站:Stat 501